Sparse2DGS: 3장 이미지만으로 3D Reconstruction 하기
Paper Link : https://arxiv.org/abs/2504.20378
Abstact
3D Reconstuction 기술이 빠르게 발전하고 있다.
기존에 하나의 장면을 처리하기 위해 70~100장의 이미지가 필요했던 3D Gaussian Splatting이나 2D Gaussian Splatting을 단 3장의 이미지만으로 구현하면서도, 처리 시간을 며칠에서 100초로 단축시킨 Sparse2DGS 논문을 리뷰하려 한다.
Introduction
GS가 novel view synthesis에서 빠르고 효율적인 방법론이었지만, multi-view image가 여러장 들어가야한다는 단점이 있었다 이렇게 많은 수의 input image가 필요했던 주요 이유는 SfM으로 부터 얻은 sparse point cloud의 3D Point가 불충분했기때문에 gaussian primitive를 초기화하기에 부족했기때문이다. 이 Sparse2D GS에서는 오직 3장의 이미지만으로 물체를 reconstruct하는 2D GS를 향상시키는 3D Reconstruction 방법론을 제시한다. 정확하고 dense한 3D Point cloud를 생성하기 위해서 COLMAP MVS와 함께 DUSt3R을 사용한다. 두가지 방식으로 2D Gaussian을 초기화한다. DTU Dataset에서 실험했고, 훌륭한 결과를 보여준다.
multiple image를 사용한 3D Reconstruction 방법론은 MVS 기반 방법론과 deep learning 방법론이 존재하는데 두 방법론 모두 많은 수의 이미지를 통해 image correspondence에 의존하기때문에 적은 수의 이미지가 들어가게 되면 정확도가 떨어진다. NeRF의 발전으로 SDF와 volume rendering을 사용하는 방식이 제안되었다. 학습기반 MVS방법론과 달리 NeuS는 각 scene에 대한 이미지만을 사용해 radiance field를 최적화하기때문에 사전훈련이나 깊이정보에 대한 정답값이 필요없다. 사전훈련된 모델을 파인튜닝하여 input image를 적게 가져가는 방법론들이 존재하긴한다. 이러한 방법론들의 정확도는 NeuS보다는 높지만 그들은 사전훈련되는 과정에서 학습시간과 필요한 데이터가 많이 요구된다.
Method
GS의 속도와 정확도의 이점을 가져가면서 적은 input 이미지로 부터 3D 재구성을 하기위해서는 가우시안 초기화를 위해 dense하고 정확한 3D Point를 얻어야한다. 3장의 이미지로 부터 3D reconstruction하기 위해서 2D GS에다 DUSt3R, COLMAP MVS를 활용하는 방법론을 제안한다.
COLMAP MVS와 DUSt3R을 활용해서 input으로 부터 재구성된 3D Point Cloud를 재구성한다. 다음에 3D Point cloud를 dense하고 정확한 3D Point cloud를 얻기 위해서 outlier들을 제거한다. 그리고 나서 3D Point cloud를 2D Gaussian 초기값으로 이용해 radiance field를 최적시킨다. 최종적으로 각각의 viewpoint에서의 depth map은 최적화된 radiance field를 사용해서 랜더링된다. 그리고 물체의 표면은 그들을 통합해서 재구성된다.
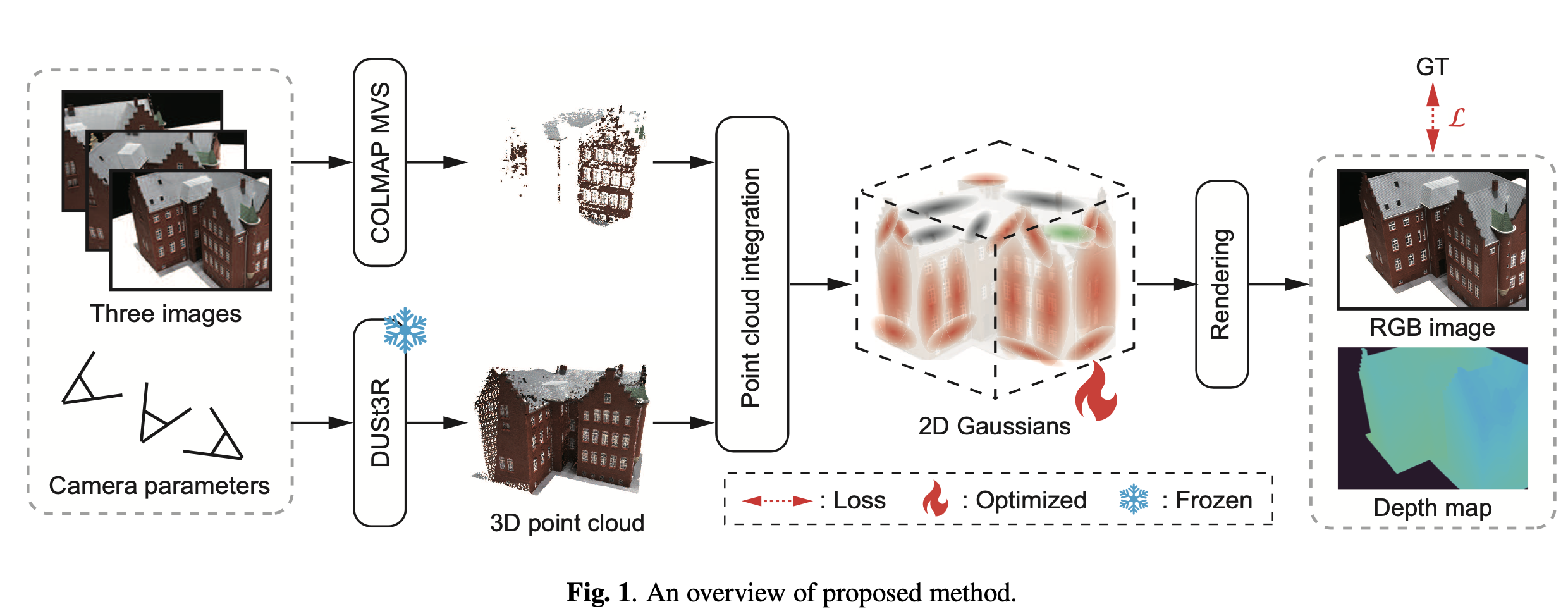
이 논문에서 사용했던 방법중 일부인 DUSt3R는 WxH 픽셀을 고려했을때, 각 픽셀의 3D 좌표로 표현된다. 그래서 output이 X(WxHx3)이 나온다. 그러므로 각 관점에 대한 dense한 3D point cloud는 X로부터 얻을 수 있다. 두개나 더 많은 이미지가 input일때, 많은 stereo image쌍이 생성된다. 3D point cloud의 좌표 시스템이 다양하기때문에 그들은 하나의 좌표 시스템으로 통합된다. dense한 3D point cloud가 적은 수의 view point 이미지로 부터 얻을수있음에도 불구하고 DUSt3R은 충분한 정확도를 가지고 3D Point cloud의 좌표에서 많은 에러가 발견되기 때문에 3D point cloud를 제공할 수 없다. 그래서 DUSt3R에 덧붙여서 COLMAP MVS에 의해 구축된 3D Point cloud를 사용한다.
구체적으로, DUSt3R로 부터 얻은 3D point cloud가 특정 사이즈의 복셀로 다운샘플링된다. 이 논문에서 우리는 경험적으로 0.005로 사이즈를 설정했다.
이웃하는 3D 점들로부터 큰 거리를 가진 3D Point들은 outlier로 간주되어서 확률적으로 이상치 제고 알고리즘을 사용해 제거된다. 그러면 ICP 알고리즘으로 DUSt3R과 CKLMAP MVS의 point cloud를 align한다. 이렇게 통합된 3D Point cloud점을 가우시안의 초기값으로 사용하여 few shot임에도 불구하고 radinace filed의 local solution을 예방할 수 있다.
이렇게 초기값만 다르게 적용하고 Loss값은 2D GS와 똑같이 color reconstruction loss와 depth distortion loss, normal consistency loss를 함께 쓴다.
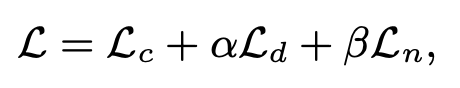
Experiments
실험할때, 빛을 굉장히 많이 반영하는 샘플들 (ex. DTU Dataset에서 69, 97, 110번호 scan 데이터셋)은 객체와 강한 반사를 담고있기때문에 제외했다고 한다. 이 실험에서는 Chamfer Distance 를 평가 메트릭으로 사용되는데 식은 다음과 같다.
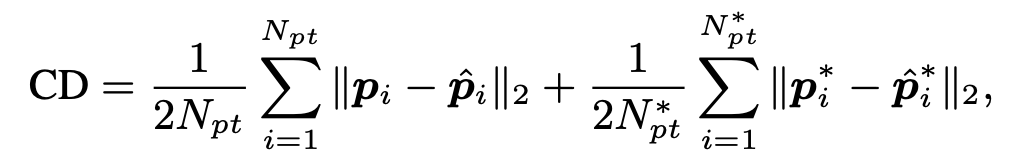
Chamfer Distance는 두 3D point cloud 간의 유사성을 측정하는 지표로, 정확한 일대일 대응점을 찾기 어려운 상황에서 근사적 거리 측정을 수행한다.
주어진 두 point cloud가 존재한다고 가정하자.

S₁의 각 점에서 S₂ 내 가장 가까운 점과의 L2 거리의 제곱을 계산하여 평균하고, S₂의 각 점에서 S₁ 내 가장 가까운 점과의 L2 거리의 제곱을 계산하여 평균한 후, 이 두 값을 합산한다. 이는 두 point cloud 간에 정확한 일대일 대응점(correspondence)을 찾기 어렵기 때문에, 각 점에서 상대방 point cloud의 가장 가까운 점을 찾아 근사적으로 거리를 측정하는 방식이다.
논문에서 언급된 변수들을 명확히 정리하면, $N_{pt}$는 재구성된 3D point의 개수이고, $N_{pt}$는 Ground truth 3D point의 개수이다. i는 3D Point의 index 번호라서 $p{i}$는 재구성된 point cloud의 i번째 점의 3D 좌표이고, $p^{*}_{i}$는 Ground truth point cloud에서 pᵢ와 가장 가까운 점의 3D 좌표이다.
일반적으로 3D GS에서는 초기에 sparse한 점들로부터 시작하기때문에 학습과정에서 필요에 따라 새로운 Gaussian을 추가하는 densification과정이 필요하지만, Sparse2D GS에서는 dense한 3D Point cloud로 시작하기때문에 densification를 수행하지 않는다. 대신 초기화과정에서 얻어진 2D Gaussian 파라미터를 최적화한다. 이 최적화를 위한 optimizer로는 Adam을 사용했다.
또한 3D 재구성 과정에서는 mask 이미지를 depth map에 적용하여 배경 없이 객체 표면만 재구성하였다. 실험환경은 RTX 4090 GPU 1대였다. 제안된 메소드의 최적화 시간은 100초였고, 3D 재구성 시간은 대략 10초였다.
다른 MVS 방법론 COLMAP, SDF 기법들인 (SparseNeuS, ReTR, UFORecon), GS기반의 방법론인 2D GS, Foundation model인 DUSt3R과 비교해보았다. 학습 기반의 MVS 방법론들은 이미 앞의 기법들의 논문에서 비교를 해놓았기때문에 따로 실험에 포함하지 않았다. 이 paper에서는 적은 수의 이미지로 부터의 3D 재구성이라는 task에 집중하였기때문에 이 실험에서의 UFORecon는 사전훈련에서 전략을 사용하지 않는다.

DTU 데이터셋으로 실험을 진행했고, CD를 평가 메트릭으로 사용하여 적은 값이 더 좋은 성능을 의미하는데, 제안된 방법이 거의 모든 장면에서 최고 또는 2위의 정확도 달성하였다. 기존의 SOTA모델인 UFORecon의 경우 대량의 다시점 이미지 필요하고 사전훈련에 며칠이 걸리는등 효율성 측면에서 비교해보았을때 단 3장의 이미지만 사용하여 장면당 약 100초만에 객체 표면 재구성할 수 있는 Sparse2D GS가 더 효율적이다.
논문에서 “ In this section, we evaluate the performance of the proposed method through the experiments on 3D reconstruction from three input images” 이렇게 언급한 것으로 보아 학습에 쓰인 이미지는 단 3장이었음을 볼때, 상당히 놀라운 결과라고 생각한다.
Take home Messages
💡 1. Dense하고 정확한 초기 point cloud가 핵심
기존: Sparse Points → Densification during training
제안: Dense Points → Parameter optimization only
💡 2. DUSt3R 같은 사전훈련된 모델을 효과적으로 조합