이제껏 우리가 배웠던 라우터는 다 이상적인 상황의 라우터였다. 실제로는 다르다.
1. 이상적인 모델에서는 네트워크 내의 모든 목적지와 경로를 라우터가 완벽하게 알고 있고, 이를 기반으로 최적의 경로를 계산할 수 있다고 가정한다. 그러나 실제 네트워크는 매우 방대하다. 실제 인터넷은 수십억 개의 목적지를 포함하며, 이러한 모든 목적지에 대한 정보를 모든 라우터가 알고 있을 수는 없다.
2. 이상적인 모델에서는 모든 라우터가 동일한 관리 하에 있으며, 모든 라우터가 동일한 정책과 프로토콜을 사용하여 협력한다고 가정한다. 그러나 실제 네트워크는 여러 조직, 기업, 정부 기관 등 다양한 주체들이 관리하므로 동일 정책을 사용하지 않는다.
인터넷의 확장 가능한 라우팅 접근 방식에서는 "자율 시스템(Autonomous System, AS)" 개념을 사용한다.
AS는 하나의 관리 단위로 운영되는 네트워크 또는 네트워크 그룹으로, 라우팅 정책을 독립적으로 결정하고 실행한다.
Intra-AS 라우팅
Intra-AS 라우팅은 하나의 자율 시스템 내부에서 일어나는 라우팅을 의미한다.
동일한 관리 단위 내의 라우터들이 서로 통신하여 최적의 경로를 찾고 데이터를 전송한다.
AS내의 네트워크 관리자가 이 AS 내에서는 routing 방법으로는 어떤 방법을 선택하고, cost는 어떻게 부여할 지를 전부 정할 수 있다.
여러가지 Intra-AS protocol이 있는데,
RIP (Routing Information Protocol)
- 거리 벡터(Distance Vector) 방식을 사용하는 라우팅 프로토콜
- 자신의 라우팅 테이블 업데이트 여부와 상관없이 주기적으로 이웃 라우터에게 자신의 존재를 알림
EIGRP (Enhanced Interior Gateway Routing Protocol)
- 거리 벡터 방식을 기반으로 하는 CISCO 독자적인 라우팅 프로토콜
- 표준 라우팅 프로토콜은 아님
OSPF (Open Shortest Path First)
- 링크 상태(Link State) 방식을 사용하는 표준 라우팅 프로토콜
- 개방형이므로 라우터 제조업체들이 사용 가능
- 라우터들이 IP를 이용해 자신의 상황을 전파하고, 다익스트라 알고리즘으로 전체 토폴로지 정보를 바탕으로 포워딩 테이블 계산
- 인증 절차를 통해 악의적인 비용 정보 전파에 대한 보안성 확보
Hierarchical OSPF
Hierarchical OSPF는 OSPF의 확장된 버전으로, OSPF는 계층적으로 도메인을 local area와 backbone들로 나누고, 이를 각각 area라고 칭한다. Link State 방법으로는 라우터들이 broadcast하게 자신의 정보를 계속 뿌려줘야하는데 이가 부담이 되어서 확장성을 위해서 area 단위로 나누었다. 예를 들어 area 1, area 2, area 3이 있다고 가정하고 각 area에서 gateway 역할을 하는 area border router들과 다른 라우터들이 합쳐저 backbone area를 이룬다.
Inter-AS 라우팅
네트워크에서 서로 다른 자율 시스템(AS: Autonomous System) 간의 통신을 위한 라우팅 방식을 Inter-AS(Autonomous System) 라우팅이라고 한다.
Intra-AS 라우팅을 통해 전달받은 목적지까지의 연결 정보(reachability information)를 다른 AS와 공유할 때 Inter-AS 라우팅이 사용된다. 다른 네트워크와 통신하기 위해서는 표준 프로토콜을 준수해야 하며, Intra-AS 라우팅의 도움을 받을 수밖에 없다.
Inter-AS 라우팅 프로토콜로는 BGP(Border Gateway Protocol)가 있습니다. BGP는 각 AS에 두 가지 방식으로 동작한다.
- eBGP(Exterior BGP): 외부 이웃 AS에서 목적지 정보를 받는 프로토콜
- iBGP(Interior BGP): eBGP로 전달받은 정보를 AS 내부에 전파하는 프로토콜
목적지로 가는 최적의 경로를 결정할 때는 단순히 도달 가능 여부뿐만 아니라 '정책'에 따라서도 결정된다.
어떤 경로를 선택할지, 거부할지, 심지어 무엇을 광고할지도 policy가 영향을 준다.
Path Attribute와 BGP Routes
BGP는 경로 정보를 광고할 때 접두사(prefix)와 속성(attribute)의 형태로 전달한다.
- 접두사(prefix): 광고되는 목적지 네트워크를 의미한다.
- 속성(attribute)
- AS-PATH: 접두사가 광고되면서 거쳐온 AS(Autonomous System)들의 순서가 기록된 리스트이다.
- NEXT-HOP: 외부 AS에서 해당 경로 정보를 광고한 AS의 IP 주소이다. (이웃 AS)
예를 들어, AS 100에서 192.168.1.0/24 네트워크 접두사를 광고한다고 가정해보자. 이 경로 정보는 AS 200 -> AS 300 -> AS 400 순서로 전파되었다면, AS 400에서는 다음과 같은 정보를 가진다.
- Prefix: 192.168.1.0/24
- AS-PATH: 100, 200, 300, 400 (거쳐온 AS 순서)
- NEXT-HOP: AS 300의 IP 주소
AS-PATH를 통해 이 경로가 어떤 AS들을 거쳐왔는지 추적할 수 있고, NEXT-HOP은 실제 다음 전송 대상 AS를 나타낸다. BGP 라우터는 이러한 속성 정보를 바탕으로 최적 경로를 선택하게 된다.
만약 gateway router가 목적지에 도달하기위한 path로 여러가지를 전달받았다면 poicy에 기반하여 선택한다.
BGP messages는 TCP 연결을 기반으로 교환된다.
또한 BGP message는 다음과 같은 종류의 메세지를 담을 수 있다.
1. OPEN : 최초로 연결설정하고, 인증하기위한 메세지이다.
2. UPDATE : 새로운 path를 광고하는 메세지이다.
3. KEEPALIVE : 변화가 없더라도 계속 살아있음을 알려주는 메세지이다.
4. NOTIFICATION : 이전 메세지에 에러가 있음을 알려주거나 Connection이 닫힐때 사용된다.
어떻게 BGP가 path를 광고를 진행할까?

우선 1c는 1d, 1a, 1b에게 X를 가는 길은 1c에게 줘야한다는 것을 iBGP를 통해서 전달한다.
1d에서는 그러면 OSPF intra-domain routing으로 1c로 가기위해서 interface 1번을 사용해야된다는 것을 알게된다. 그리고 X로 가기위해서 interface 1번을 사용해야된다는 것을 알게된다.
1a 입장을 볼까? 1a에서 X로 가는 목적지를 찾는다고 가정해보자.
1a 도 1d와 마찬가지로 X로 가려면 1c에게 전달해야한다는 정보를 들었고, 1c로 가기위해서는 1b나 1d로 가야한다는 사실을 알고있다. 하지만 내부 policy에 의해서 2번 인터페이스로 가서 1d를 거리는 경로를 선택했다고 가정하자. 그렇다면 1a에서 1c로 가려면 interface 2번을 사용해야하고, 마찬가지로 목적지 X로 가려면 interface 2번을 사용해야한다.
intra-AS와 inter-AS routing 기법은 왜 구분하는 것일까?
intra-AS는 하나의 관리주체가 있고, 그 영향을 받는 라우터들이 있으므로 policy가 별로 중요하지 않다. 차라리 효율성(performance)을 더 중요시한다.
하지만 inter-AS는 서로 다른 관리주체가 있으므로 이제 policy를 철저하게 지켜야한다.
이렇게 intra-AS 기법과 inter-AS 기법을 구분하면 확장성측면에서 좋다. 만약 이 두 기법을 사용하지 않는다면 모든 목적지에 대한 정보를 가지고 있어야하는 상황이 생긴다.
Hot potato routing
Hot potato routing은 손에 뜨거운 감자를 가지고 있을때 얼른 주변으로 털어버리고싶은 방법을 말한다.
보통의 경우라면 AS-PATH가 더 짧은 경로로 갈것이지만, Hot potato routing에서는 내 router내에서 주변 router들의 link weight가 더 작은 곳으로 가는 방법을 택한다. 즉, 다시 말해 inter-domain cost만 신경을 쓰고 intra-domain cost에는 신경을 쓰지 않는 방식이다.
광고를 통한 정책 구현
1. ISP A, B, C가 있을때 각 ISP들은 자신의 고객만 신경쓰면 된다.
다시 말해, ISP A의 고객인 w에서 ISP C의 고객인 y로 가는 경로가, w -> ISP A -> ISP B -> ISP C -> y로 가는 경로가 있을 수 있지만, ISP B입장에서는 y와 w 모두 자신의 고객이 아니기때문에 중개를 해줄 이유가 없다. 따라서 ISP B는 ISP A에게 y로 가기위해서 C로 가는 경로가 있다는 사실을 광고해줄 필요가 없다는 말이다.
2. ISP는 일반적으로 provider network에서 customer network로 트래픽을 전달하는 경로를 채택하지 않는다. 그 이유는 customer network가 ISP에게 서비스 비용을 지불하는 고객인데, 만약 ISP가 customer network의 대역폭을 사용하여 다른 고객에게 서비스를 제공한다면, 고객에게 제공해야 할 서비스 품질이 저하될 수 있기때문이다.
BGP 경로 설정의 우선순위는
1. policy가 제일 중요하며
2. AS-PATH(지나는 AS개수) 길이가 짧은 것이 중요하며
3. NEXT-HOP router가 가까운 것이 중요하며 (Hot potato routing)
4. additional criteria (또 다른 기준이 적용될 수 있다.)
Control Plane 입장에서 본 SDN
전통적인 방식으로는 Hardware와 software가 합쳐진 라우터와 middleware를 상품을 팔곤했는데 2005년 이후부터 소프트웨어를 따로 구현한 SDN 아이디어가 인기를 끌었다. 하나의 서버(컨트롤러)가 네트워크 전체의 토폴로지와 상태 정보를 수집해 이를 바탕으로 최적의 라우팅 테이블을 계산한 후 모든 라우터마다 전달한다.
왜 이렇게 중앙화된 알고리즘을 사용했을까?
1. 네트워크 관리가 훨씬 쉽다.
2. 분산 알고리즘에서는 각 노드가 로컬 정보만을 가지고 의사결정을 내리므로 계산하는 과정이 오래 걸리거나 어렵다. 하지만 중앙 집중식 알고리즘에서는 모든 네트워크 상태를 고려해 최적의 라우팅 테이블을 계산할 수 있다.
3. SDN은 소프트웨어를 통해 네트워크를 프로그래밍할 수 있어 유연성을 제공한다. 네트워크의 동작을 동적으로 제어하고 최적화시킬 수 있다.
예를 들어 a 라우터가 1번 경로와 2번 경로중 최소 경로인 1번 경로가 아닌 2번 경로로 가고싶을때, 이를 전통적인 방식에서 2번 경로로 가도록 바꾸기 위해서는 각 루트에 설정된 cost를 수동으로 조정하거나 policy를 바꿔야한다. 또한 두 경로로 데이터를 조금씩 나눠보내는 것이 불가능했다. 또는 같은 목적지로 보내더라도 구분을 하고싶을때 기존의 방법으로는 구분할 수 없었다. 이러한 문제들을 SDN이 해결할 수 있었다.
Software defined networking(SDN)
SDN을 다시한번 살펴보자.
우리는 network layer를 크게 각 스위치마다 flow table을 참조해 forwarding시키는 data plane부분과 control plane부분으로 나누어 살펴보았다.
Data plane에서의 switch는 빠르고 간단하게 설계되며, 일반적인 하드웨어를 사용한다. 계산된 flow table은 컨트롤러 감독 하에 스위치들에 설치된다.
northbound API
네트워크 제어 애플리케이션(라우팅, 접근 제어, 부하분산)이 SDN 컨트롤러와 상호작용하여 네트워크 동작을 정의합니다. 그래서 네트워크 제어 애플리케이션을 brain 역할이라고 말합니다. 문제해결을 위한 논리적인 알고리즘을 포함하고 있기 때문입니다. 애플리케이션과 SDN 컨트롤러들이 상호작용할 시 네트워크 제어 애플리케이션과 통신을 목적으로 하는 northbound API를 사용합니다. SND 컨트롤러는 네트워크 제어 애플리케이션에게 네트워크 상태 및 통계 정보와 같은 것들을 제공하면, 네트워크 제어 애플리케이션은 이를 바탕으로 네트워크 정책 및 규칙을 설정합니다. 이를 전달받는 SDN 컨트롤러는 이러한 규칙들을 바탕으로 여러가지 중요한 역할을 수행한다.
southbound API
southbound API는 data plane switch와의 통신을 목적으로 하는 API이다. SDN 컨트롤러는 스위치에 구체적인 명령을 전달한다. 스위치는 이러한 명령을 바탕으로 패킷을 전달하고 본인들이 가지고 있던 flow table을 업데이트한다. OpenFlow 프로토콜이 southbound API에 속한다고 생각하면 된다.
SDN 구성요소
분산 SDN 컨트롤러는 분산 시스템으로 구현되었는데, SDN 컨트롤러가 단일 중앙 집중식 엔티티로 존재하지 않고 여러 개의 컨트롤러가 분산되어 협력하여 네트워크를 관리한다는 의미이다. 확장성, 견고성 측면에서 유리하다.
SDN 구성요소로는 크게 3가지로 분류된다.
1. 네트워크 제어 어플리케이션 interface layer
네트워크 제어 애플리케이션과의 상호작용을 위한 API와 추상화를 제공한다.
- Network Graph : 네트워크의 전체 구조를 그래프로 관리
- RESTful API :RESTful API를 통해 외부 애플리케이션이 SDN과 통신할 수 있도록 하였음.
- Intent : 네트워크의 의도를 설정하고 이를 실현하기 위한 정책을 정의
2. 네트워크의 링크, 스위치 서비스 상태를 관리하는 분산 DB
네트워크의 상태를 전반적으로 관리하는 분산 데이터베이스 시스템을 구성한다.
- Statistics : 네트워크의 다양한 통계 정보를 수집하고 관리
- Flow tables : 스위치의 플로우 테이블 정보를 관리
- Link state info : 네트워크 링크 상태 정보를 관리
- Host Info : 네트워크에 연결된 호스트 정보를 관리 (SDN에서 다루는 것이 꼭 router 정보만은 아니고 end system 인 host들의 정보들에 대한 idea도 적용가능하다.)
- Switch Info : 물리적으로 이 스위치가 몇개의 Interface를 가지고 있는지..
3. Communication
SDN 컨트롤러와 네트워크 장비 간의 통신을 담당한다.
- OpenFlow : SDN 컨트롤러와 스위치 간의 통신 프로토콜
- SNMP : 네트워크 장비의 관리 및 모니터링을 위한 프로토콜
OpenFlow protocol
메세지를 전달하기 위해 TCP 사용.
컨트롤러와 스위치 사이의 정보 전달을 하는 프로토콜.
OpenFlow 프로토콜은 SDN 컨트롤러 내에서 네트워크 장치간의 통신을 위한 표준 프로토콜이지만 OpenFlow API는 SDN 컨트롤러 내에서 OpenFlow 프로토콜을 사용하여 네트워크 장치를 제어할 수 있는 프로그래밍 인터페이스이다. API는 일반화된 forwarding action을 명시하기 위해 사용된다.
SDN의 API는 네트워크 제어 애플리케이션과 SDN 컨트롤러 간의 고수준 명령을 받아들여 이를 네트워크 장치(스위치)에서 실행 가능한 저수준 명령으로 변환한다. 이러한 명령은 일반적으로 여러 개의 메시지 형태로 전달되어 네트워크 장치와 상호작용하게 된다.
이때 고수준 명령의 경우 '특정 IP 범위의 트래픽을 우선 처리하라'를 예시로 들수 있고, 네트워크 장치가 이해할 수 있는 저수준의 구체적인 명령은 플로우 테이블 엔트리 추가, 특정 포트로의 패킷 포워딩, 패킷 드롭 등의 구체적인 액션이 포함된다.
Controller가 switch에게 메세지를 보내는 동작
Controller가 Switch에게 보내는 메세지는 어떤 것으로 구성되는지 알아보자.
1. 특징 : 컨트롤러가 switch에게 쿼리를 날려 네트워크의 상태를 알아본다. 컨트롤러가 네트워크의 전체 트래픽 상황을 파악하고 싶을 때 각 스위치의 트래픽 통계 정보를 요청하여 네트워크의 상태를 모니터링한다.
2. 설정 : 컨트롤러가 스위치의 상태를 설정하는데 사용한다. 특정 트래픽이 우선 처리되도록 A 스위치의 우선순위 파라미터를 설정할 때 사용한다.
3. modify-statement : flow table 정보를 추가,삭제,변경하라는 지시.
4. packet-out : 컨트롤러가 특정 패킷을 특정 포트로 포워딩하도록 지시. 컨트롤러가 패킷을 분석한 후에 특정 패킷을 보내라고 스위치에 지시하는 경우가 예시로 있겠다.
switch가 Controller에게 메세지를 보내는 동작
1. 패킷인 : 패킷이 컨트롤러에게 제대로 된 정보가 맞냐고 분석해달라고 문의하는 과정이다.
2. flow-removed : 컨트롤러가 flow table에서 특정 entry를 삭제하라고 지시했을때 제대로 지웠다는 대답이다.
3. port status : 컨트롤러에게 자신의 port 상태가 바뀌었음을 알려준다.
OpenFlow API가 이를 저수준의 OpenFlow 메시지로 변환해주기때문에 네트워크 운영자가 저수준의 복잡한 프로토콜 명령(OpenFlow 메세지를 직접 적지않고) 대신 고수준의 프로그래밍 인터페이스(OpenFlow API)를 사용해 네트워크를 관리하고 제어할 수 있다.
컨트롤러와 스위치 간의 상호작용
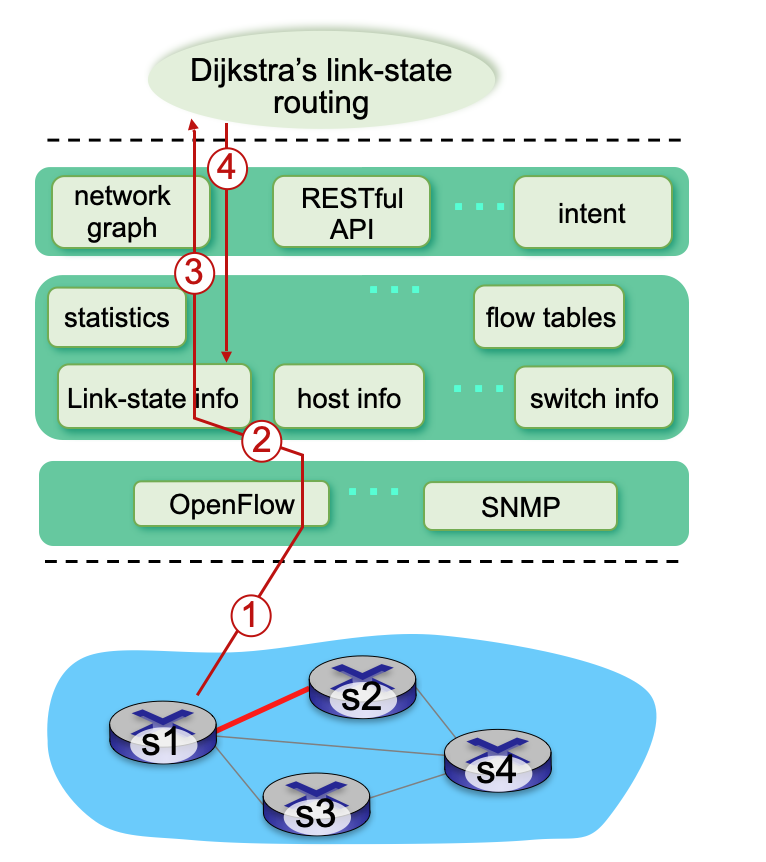
1) s1과 s2 사이의 연결되는 링크로 이어지는 s1 스위치의 포트가 고장난 상황이다. 이때 S1 스위치는 OpenFlow port status 메세지를 통해 컨트롤러가 링크 장애가 일어났음을 알린다.
2) SDN 컨트롤러는 S1 스위치로 부터 OpenFlow 메세지를 수신하고 Link-state info를 업데이트한다. 이는 컨트롤러의 분산 데이터베이스에 반영된다.
3) 링크 상태 변경이 발생할때마다 호출되도록 미리 등록되어있는 다익스트라의 라우팅 알고리즘 애플리케이션이 호출된다.
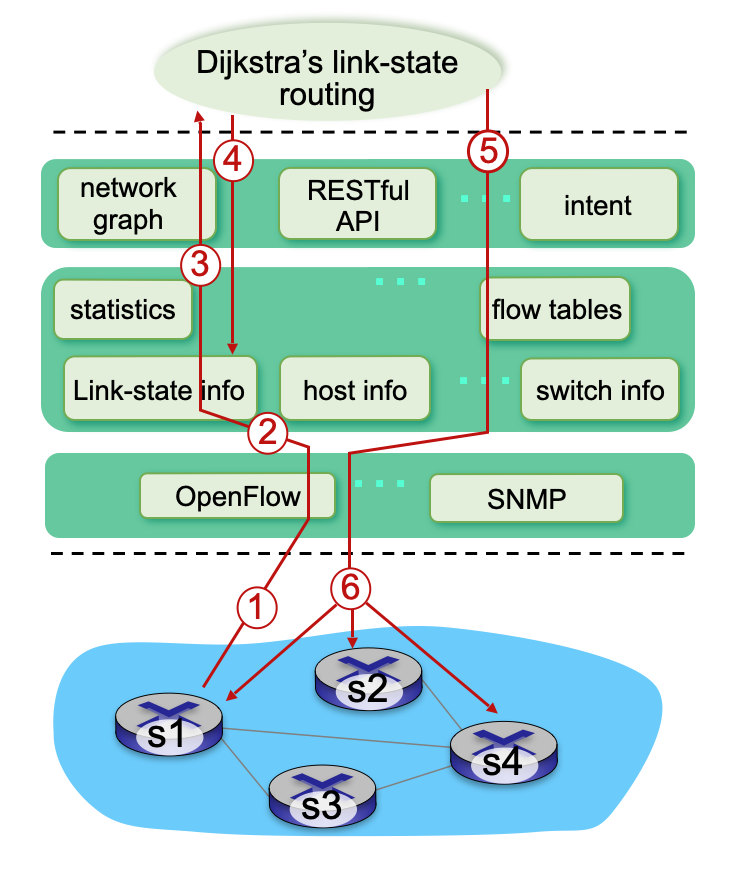
4) 다익스트라의 라우팅 알고리즘 애플리케이션은 네트워크 그래프 정보와 링크 상태 정보를 컨트롤러로부터 접근하여 정보를 가져온다. 그리고 그 새로운 정보들로 새로운 경로를 계산한다. 이 과정에서 최신의 네트워크 상태를 반영하여 최적의 경로를 재계산한다.
5) 링크 상태 라우팅 애플리케이션이 SDN 컨트롤러의 flow table 계산 구성요소와 상호작용하여 새로운 플로우 테이블이 계산된다.
6) SDN 컨트롤러는 OpenFlow 프로토콜을 사용하여 업데이트가 필요한 스위치에 새로운 플로우테이블을 설치한다. 이렇게 하여 s1, s2, s4 스위치에 새로운 플로우 테이블이 설치되어 네트워크가 최적의 상태로 동작한다.
SDN이 당면하고 있는 과제
1) Control plane 강화 : Control plane이 신뢰할 수 있고, 확장 가능하며, 보안이 강하고 견고성있고, 확장성있는 분산 시스템이 되도록 해야한다.
2) 특정 요구사항을 충족하는 프로토콜이 필요하다. (ex. 실시간성, 초고신뢰성, 초고보안 등등)
3) 인터넷 확장성 : 단일 자율 시스템(AS)를 넘어서 확장될 수 있어야한다.
등등..
SDN과 전통적인 네트워크 프로토콜의 미래
기존 SDN이 할 수 있는 방법이 forwarding 뿐이었다가 확장되었다.
컨트롤러가 라우터가 보고한 혼잡 수준에 따라 송신 속도를 설정할 수 있다. 기존 방법은 TCP에 기반으로 한 congestion control이라서 end system이 혼잡을 추론하였다. 혼잡 위치를 정확히 알지 못한다는 단점이 존재했다.
ICMP : internet control message protocol
host와 router가 네트워크 상태를 알리거나 문제를 보고하였다.
ICMP는 IP 데이터그램에 포함되어 전송된다. ICMP 메시지는 타입, 코드, 그리고 오류를 발생시킨 IP 데이터그램의 첫 8바이트로 구성된다. (identifier와 flag가 포함된 두번째 줄까지)
Traceroute와 ICMP
1. 소스에서 목적지로 TTL값이 N인 UDP 세크먼트 전송
2. N번째 라우터에 N번쨰 데이터그램 도착시 라우터는 데이터그램을 폐기하고, 소스에게 ICMP 메시지(type 11, code 0) 를 보낸다. 이 의미는 TTL이 만료되었음을 의미한다. 이때 ICMP 메시지에는 라우터의 IP 주소가 포함되므로, N번째 hop의 IP 주소를 알 수있는 것이다.
중지기준
- 목적지 호스트 도달 시: UDP 세그먼트가 최종적으로 목적지 호스트에 도달하면 중지
- 목적지에서 ICMP "포트 도달 불가" 메시지 반환: 목적지에서 ICMP 포트 도달 불가(type 3, code 3) 메시지를 반환
- 소스 중지: 이 메시지를 수신하면 소스는 더 이상 프로브를 전송하지 않습니다.
'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| [Network Layer 03] Control Plane (1) | 2024.05.28 |
|---|---|
| [ Network Layer 02] Data Plane (0) | 2024.05.25 |
| [ Network Layer 01] Data Plane (1) | 2024.05.20 |
| [Tranport Layer 03] TCP의 연결 설정 (0) | 2024.05.03 |
| [Transport Layer 02] TCP (0) | 2024.05.01 |


댓글