본 글의 논문 Going Deeper with Convolution 링크 : https://arxiv.org/abs/1409.4842
Going Deeper with Convolutions
We propose a deep convolutional neural network architecture codenamed "Inception", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The
arxiv.org
1. GoogLeNet
GoogLeNet은 유명한 CNN 아키텍처 중 하나입니다.
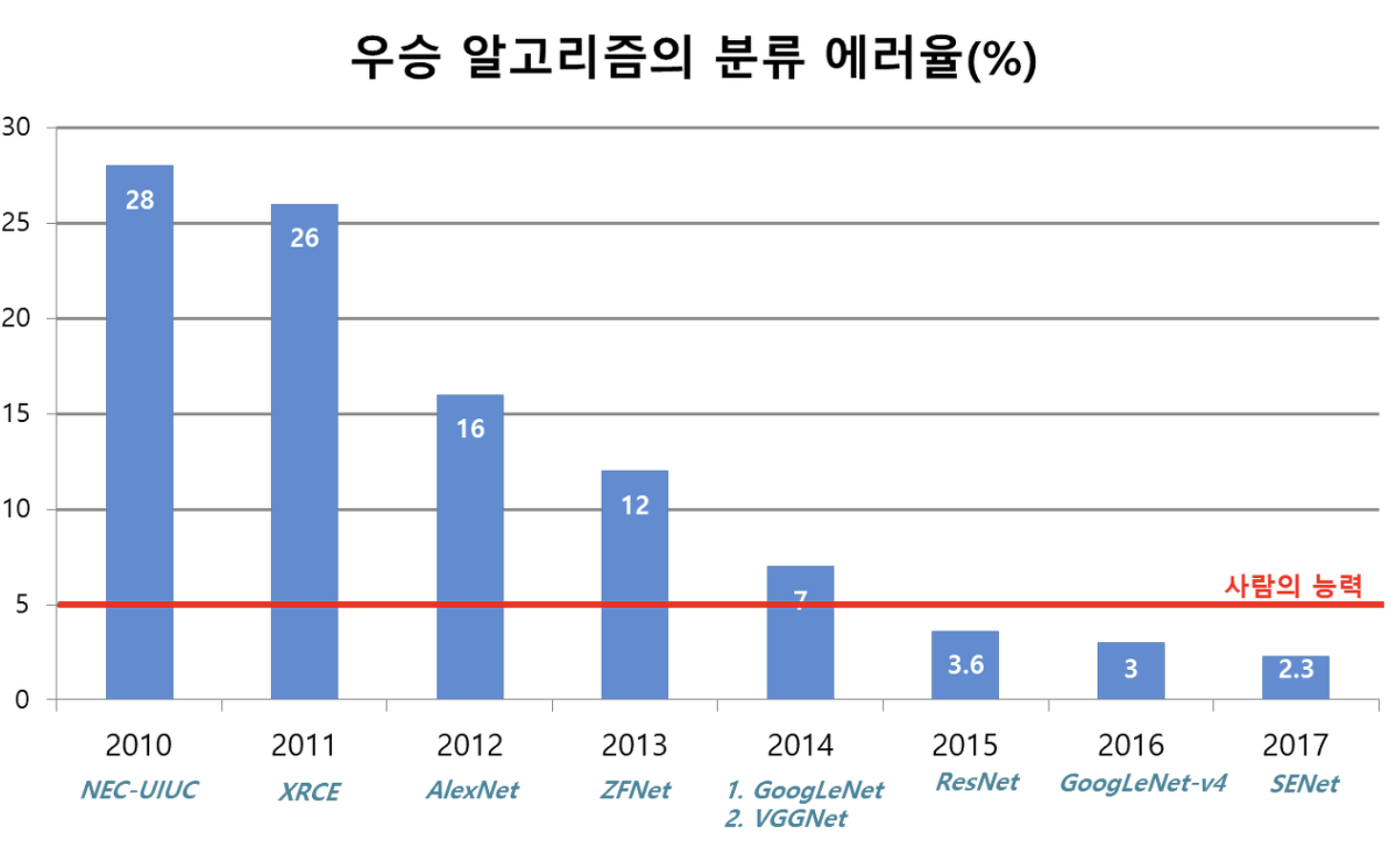
AlexNet, VGG, GoogleNet, Resnet를 한 번씩 들어보셨을 것입니다. 이 모델들은 유명한 CNN Architecture이며 VGG를 제외한 3가지 모델들은 모두 ILSVRC라는 이미지 분류대회에서 1등을 한 번씩은 해봤다는 모델들입니다. ILSVRC대회는 ImageNet Large Scale Visual Recognition Challenge의 약자로 이미지 인식 경진대회입니다.
그렇다면 CNN이 뭘까요?
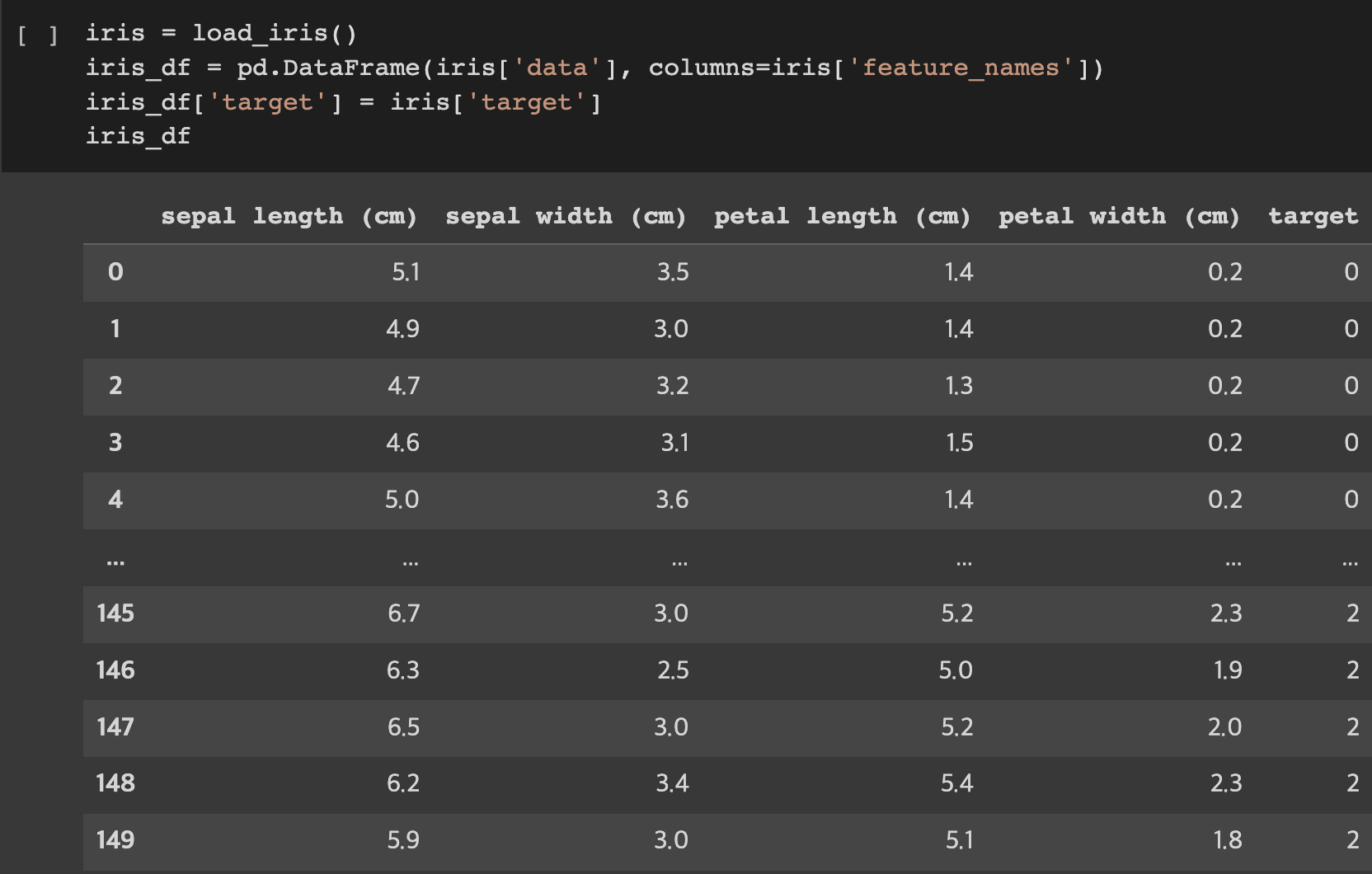
붓꽃 데이터 셋인 IRIS 데이터를 알고 계신가요?
IRIS 데이터는 1개의 붓꽃의 꽃받침의 길이, 꽃받침의 너비, 꽃잎의 길이, 꽃잎의 너비 등 N개의 피처값을 1XN으로 나타낼 수 있는 1차원 데이터의 형태입니다. 이렇게 1차원 데이터의 형태를 사용하는 신경망을 Deep Neural Network 즉, DNN이라 합니다.
오른쪽에 있는 귀여운 강아지의 사진은 붓꽃 데이터처럼 1차원의 데이터로 나타낼 수 있을까요?
나타내는 것은 가능하지만, 1차원으로 만들어진 사진 데이터로는 이 픽셀이 강아지의 털을 나타내는 흰색 픽셀인지, 흰 꽃잎을 나타내는 흰색 픽셀인지에 대한 구별이 없어지는 문제가 생깁니다.
즉, Computer vision 트랙에서 자주 다루는 이미지 데이터의 경우 붓꽃 데이터처럼 하나의 Row를 가지는 형태로 변환하는 순간 데이터는 공간정보를 잃게 됩니다. 이러한 공간정보를 유지하며 학습하기 위해 만든 신경망이 바로 CNN인 것입니다.

GoogLeNet이 2014년에 이미지를 다루는 많은 CNN 아키텍처 중 이미지 분류대회에서 1등을 차지했습니다. 하지만, 당시 그리고 현재에도 사람들에게 많이 쓰이는 모델은 1등 구글넷이 아닌 2등을 했던 VGG였습니다. 그 이유는 구글넷 모델이 응용하기가 쉽지 않았기 때문이죠.
각광받지 못한 1등, GoogLeNet의 특징
심층 신경망의 성능을 개선시킬 수 있는 방법은 신경망의 크기를 늘리는 것입니다.
크기를 늘린다는 것은 즉, 신경망 구조를 깊고, 넓게 만든다는 것이죠.
구체적으로 말하면 깊게 만든다는 것은 layer 수를 늘리는 것이고 넓게 만든다는 것은 하나의 layer를 구성하는 뉴런의 수를 늘린다는 것입니다.
하지만, 모델이 커지게 되면 파라미터 수가 늘어나게 됩니다.
파라미터 수가 늘어나게 되면 한정된 컴퓨팅 자원을 가진 상황에서 문제점이 됩니다.
구글넷은 이러한 문제없이 신경망의 크기를 늘리기 위해 Inception module을 사용했습니다.
1. GoogLeNet은 Inception module을 사용합니다.

Inception Module은 입력값에 대해 4가지 종류의 Convolution, Pooling을 수행하고 마지막에 4개의 결과를 채널 방향으로 합치는 모듈입니다. 이 모듈은 feature를 효율적으로 추출하기 위해 1x1, 3x3, 5x5의 Convolution 연산을 각각 병렬적으로 수행합니다.
왜 이와 같이 다양한 크기의 convolution 연산을 수행할까요?
이를 설명하기 위해 3X3 convolution과 5X5 convolution이 일어나는 경우를 비교해 보겠습니다.
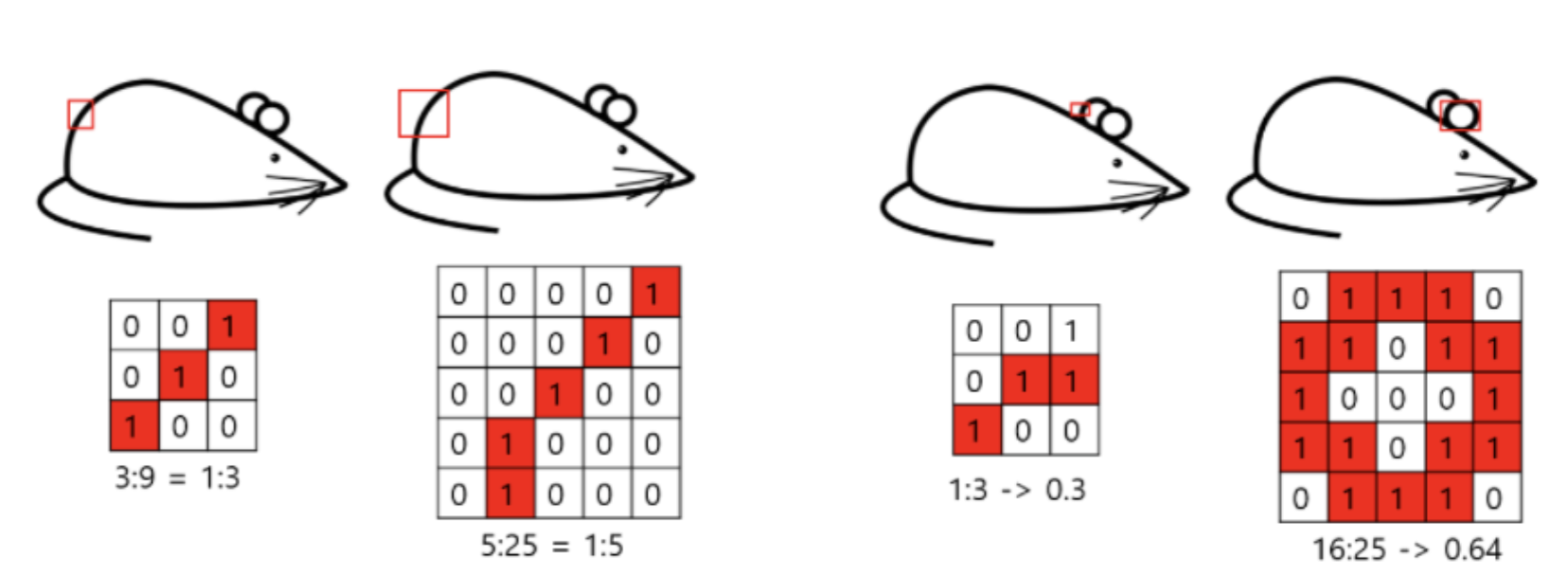
쥐를 나타낸 이미지를 보시면 왼쪽에서 두 번째 위치해 있는 사진에서 쥐의 뒤쪽 부분을 픽셀값으로 나타낸 메트릭스에서는 1로 채워진 비율이 5/25 = 0.2 정도로 sparce 한 component matrix로 표현할 수 있습니다. 하지만 맨 오른쪽에 위치한 쥐를 표현한 메트릭스는 1로 채워진 비율이 16/25 즉, 0.64로 dense 한 submatrix입니다. 이러한 dense submatrix의 경우 필터가 5X5정도로 커야 연관된 유닛을 더욱 많이 뽑아낼 수 있다는 말입니다.
이와 같이 다양한 크기로 feature값을 추출하여 효율적으로 feature 값을 뽑아낼 수 있었습니다.
그런데 이와 같이 여러 convolution을 진행하다 보면 연산량이 많아지게 됩니다.
이를 해결하기 위해 구글넷은 1x1 Conv를 사용하였습니다.
2. GoogLeNet은 1x1 Conv를 사용합니다.
1x1 convolution은 GooLeNet에 많은 영향을 끼친 Network in Network(NIN)라는 논문에서 가지고 온 아이디어입니다.
1 x 1 Convolutional layer를 사용하게 될 경우 크게 2가지의 장점이 있습니다.
1. 채널 수를 감소시킬 수 있어 차원이 축소됩니다.
이로 인해 파라미터 계산량 감소한다는 장점도 따라옵니다.
2. 비선형성이 증가합니다.
1 X 1 Convolution layer를 사용한다고 비선형성 증가로 바로 이어지는 것이 아니라, 1 X 1 Convolution layer를 사용하면서 파라미터 수가 감소하게 되고, 이러한 이점을 통해서 모델을 더욱 깊게 만들 수 있습니다. 이렇게 모델을 깊게 만드는 과정에서 기존보다 많은 수의 비선형성 활성화 함수(ReLU Activation)를 사용하므로 비선형성이 증가한다는 연쇄적인 효과를 얻을 수 있습니다.
비선형성이 증가한다는 것은 그만큼 복잡한 패턴을 좀 더 잘 인식할 수 있게 된다는 의미입니다.
1 x 1 Convolution의 사용이 왜 계산량이 작아지도록 하는지 알아봅시다.
오른쪽 아래의 그림을 보시면 위의 경우 1x1 convolution을 거치지 않고 5x5 convolution을 진행한 경우인데, 이때 연산량을 계산해 보도록 하겠습니다.
(5 * 5 * 128) 크기의 컨볼루션 필터가 64개 사용되어 최종적으로 (28, 28, 64) 크기를 가지는 결과물이 나왔습니다.
연산량은 (ouptut 의 차원) * (filter의 차원)으로 계산되어 총 160M 번의 계산량이 필요하게 됩니다.
하지만 1x1 convolution 을 사용하는 아래의 경우는 총 44.8M의 연산량을 가지는 결과를 볼 수 있습니다.
일반화하여 이해를 하자면, 연산량은 (ouptut 의 차원) * (filter의 차원)으로 계산되는데, 이때 filter의 차원을 filter의 넓이와 filter의 채널수로 나누어 (output의 차원) * (filter의 넓이 + filter의 채널)로 나누어 더해주는 방식으로 계산해 연산량 감소로 있다고 이해하시면 됩니다.
(이때, 아래의 경우에서 output의 차원이 1X1 convolution을 할 때와 5X5 convolution을 할 때 output의 차원이 동일하지 않다는 점과 filter의 넓이뿐만 아니라 filter의 개수가 영향을 미치지만 이해하기 쉬우시라 표현해 봤습니다.)
* 아래의 사진에서 params라 표현한 것은 파라미터 수가 아닌 연산량을 나타낸 것입니다.

이외의 특징을 알아보면,
3. GoogLeNet은 inception model을 낮은 layer에서는 사용하지 않았습니다.
Google 팀에서는 효율적인 메모리 사용을 위해 낮은 layer에서는 기본적인 CNN 모델의 Conv와 Pooling 연산을 적용하고, 높은 layer에서 Inception module을 사용하는 것이 좋다고 말했습니다. 입력값과 비슷하다고 볼 수 있는 낮은 layer에서는 관련되어 있는 유닛들이 집중되어 있기 때문에 단일 지역에 많은 클러스터들이 집중되어 Inception을 사용하지 않는 것이 낫기 때문입니다.
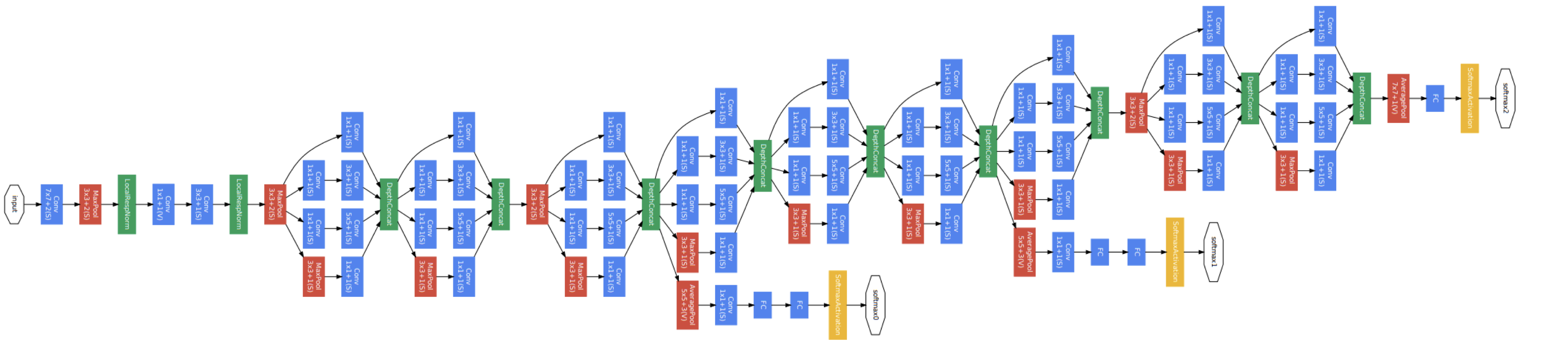
4. GoogLeNet은 auxiliary classifier 를 사용합니다.
또 다른 특징으로는 노란색 박스로 표시되어 있는 softmax가 끝 부분뿐만 아니라 중간중간에도 있다는 점입니다.
이를 auxiliary classifier라고 하는데요, Neural Network가 깊어질수록 vanishing gradient라는 문제를 해결하는 역할을 합니다.
vanishing gradient는 Training (Backpropagation)할 때, 앞 layer로 gradient가 0 근삿값으로 전달되어 training이 되지 않는 현상을 말합니다.
Auxiliary classifier는 이 문제를 해결하기 위해 중간중간에 softmax를 두어 하위 layer를 training 할 수 있도록 만들어줍니다.
다음에는 inception v1인 GoogLeNet을 발전시킨 inception v2, v3를 다룬
Rethinking the Inception Architecture for computer vision에 대해 써보도록하겠니다.
*본 내용은 네이버 부스트캠프 AI-TECH 피어세션 때 본인이 발표했던 내용을 글로 정리한 내용입니다.
참고한 블로그
https://ikkison.tistory.com/86
'AI&ML > paper review' 카테고리의 다른 글
| [paper review] 3Difftection: 3D Object Detection with Geometry-aware diffusion features (2) | 2024.07.07 |
|---|---|
| [paper review] ARES: An Automated Evaluation Framework for Retrieval-AugmentedGeneration Systems 논문 리뷰 (0) | 2024.05.19 |
| [paper review] RAG의 시작 (0) | 2024.05.02 |
| [paper review] inception의 발달 과정 (0) | 2023.04.07 |




댓글