0. Paper Link
https://arxiv.org/abs/2311.04391
3DiffTection: 3D Object Detection with Geometry-Aware Diffusion Features
We present 3DiffTection, a state-of-the-art method for 3D object detection from single images, leveraging features from a 3D-aware diffusion model. Annotating large-scale image data for 3D detection is resource-intensive and time-consuming. Recently, pretr
arxiv.org
1. Introduction
단일 시점에서 3D로 객체를 탐지하는 것은 로봇공학과 증강 현실 같은 분야에서 무엇보다 중요하기 때문에 오랫동안 컴퓨터 비전 커뮤니티의 큰 관심을 받아왔습니다. 이 작업은 카메라 parameter가 알려진 단일 이미지로부터 장면 내 각 객체에 대한 의미론적 class와 방향이 지정된 3D 바운딩 박스를 예측하기 위한 계산 모델이 필요합니다.
2D 중심으로의 발전의 한계와 노력 : view synthesis, detection head
본질적으로 이 문제는 객체 인식과위치 파악뿐만 아니라 깊이와 방향 예측을 포함하며, 상당한 3D 추론 능력이 필요합니다. 3D detector를 처음부터 학습하기 위해 주석이 달린 데이터에 의존하는 것은 라벨링에 드는 높은 비용과 노력 때문에 확장성이 없었습니다. 최근에 대규모 자가 지도 학습 모델이 이미지 표현 학습을 위한 매력적인 대안으로 부상했습니다. 이러한 모델은 견고한 의미론적 특징을 습득하며, 이는 소규모 주석 데이터셋에 미세 조정될 수 있습니다. 인터넷 규모의 데이터로 학습된 이미지 확산 모델은 이 맥락에서 특히 효과적인 것으로 입증되었습니다. 그러나 이러한 발전은 2D 중심의 발전이었으며 3D 작업에 직접 적용하는 데는 고유한 한계가 있습니다.
구체적으로, 이러한 모델은 우리의 target task에 필요한 3D 인식이 부족하고, 대상 데이터에 적용할 때 도메인 격차를 나타냅니다. 3D 격차를 해소하기 위한 시도로, 최근 연구들은 2D 이미지 특징을 3D로 끌어올리고 특정 3D 작업을 위해 이를 정제하는 방법을 제안했습니다. NeRF-Det(Xu et al., 2023)는 사전 학습된 이미지 feature 추출기를 사용하여 시점(view) 합성 모델과 detection head 를 함께 학습시켰습니다. 그러나 그들의 접근 방식은 dense한 scene view가 필요하고, 데이터 재구성을 위해 사용되는 데이터에 detection boxes가 완전히 annotation 처리되어 있어야 한다는 점에서 적용 가능성이 제한적입니다. Diffusion 모델을 사용한 새로운 시점(view) 합성에 대한 이전 노력은 유망성을 보여주었습니다
사전 학습된 의미론적 특징을 사용하려는 노력 : 3DiffTection
그러나 이러한 모델은 일반적으로 처음부터 학습되므로 사전 학습된 의미론적 특징을 사용하는 이점을 포기하게 됩니다. 우리가 알고있는한, 이러한 Diffusion feature를 3D 인식 작업에 활용하려는 노력은 없었습니다. 본 연구에서는 사전 학습된 2D 확산 모델을 3D 객체 탐지 작업에 사용할 수 있도록 하는 새로운 프레임워크인 3DiffTection을 소개합니다 .
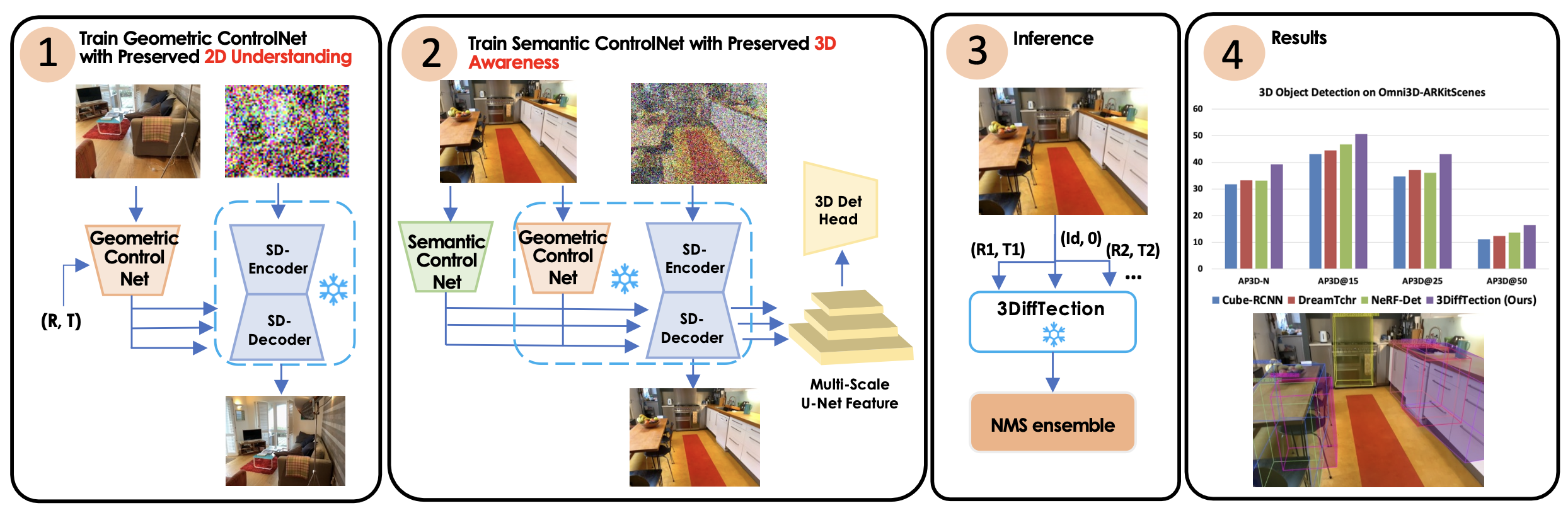
우리의 접근 방식의 핵심은 2D Diffusion feature에 3D 인식을 강화하기 위해 설계된 시점(view) 합성 작업입니다. 원본 이미지에서 잔여 특징(residual features)을 추출하고, 이를 에피폴라 기하학을 사용해 타겟 뷰로 변형(warping)합니다. 이렇게 변형된 특징들은 노이즈 제거 확산 과정을 통해 타겟 출력을 생성하는 데 사용됩니다.
이러한 왜곡된 특징은 denoising diffusion process를 통해 target output을 생성하는 데 도움이 됩니다. 우리의 방법은 종종 비디오 데이터에서 쉽게 얻을 수 있는 상대적인 위치가 알려진 이미지 쌍을 활용합니다.
비디오 데이터의 점점 더 증가하는 가용성을 감안할 때, 이는 우리의 표현 refinement solution을 확장 가능하게 만듭니다.
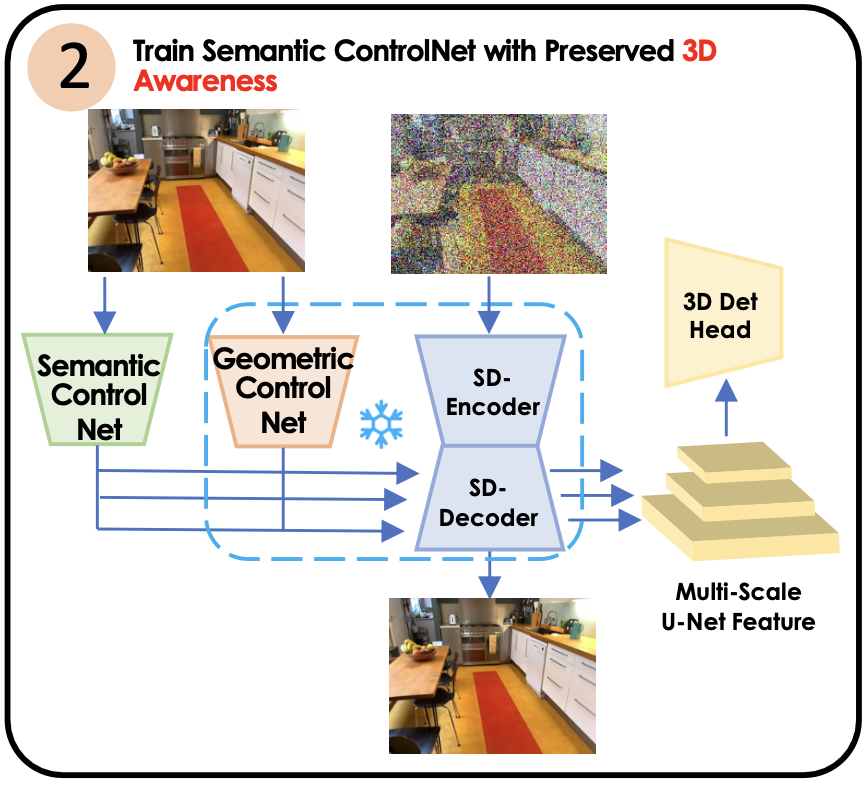
3D로 향상된 특징들을 3D 감지를 위해 사용하기 위해, 우리는 3D 박스 지도학습 하에 표준 감지 헤드를 훈련시킵니다. 우리의 모델은 기존 방법들보다 개선된 성능을 보이지만, 훈련된 특징들을 타겟 작업과 데이터셋에 맞추기 위해 추가적인 적응이 필요합니다. 훈련 데이터가 제한적이기 때문에, 모델을 직접 미세 조정(fine-tuning)하려 하면 성능 저하가 발생할 수 있습니다. 이를 해결하기 위해, 우리는 2차 ControlNet을 도입하여 특징 품질을 유지합니다.
ControlNet 도입하여 성능 저하 해소
학습 데이터가 제한되어 있기 때문에, 모델을 직접 미세 조정하여 작업과 도메인 격차를 해소하려고 하면 성능 저하가 발생할 수 있습니다. 이를 해결하기 위해 우리는 특징 품질을 유지하는 데 도움이 되는 보조 ControlNet을 도입합니다. 이 방법으로 모델의 시점(view) 합성 기능도 유지할 수 있습니다.
테스트 시에는 강화된 여러 합성된 시점에서 detection proposals을 생성하고 이를 Non-Maximum Suppression를 통해 통합함으로써 기하학적 및 의미론적 기능을 모두 활용합니다.
2. 관련 연구
2_1. 3D detection from single images
single images로 부터 3D detection을 하는 것은 어렵다. 대표적인 방법들조차도 3D 데이터셋 가용성으로 인한 의미적 정보 부족으로 3D 감지기 일반화 능력을 저해한다. 이 논문에서는 3D 데이터셋을 늘리는 것 대신에 3D 인식을 갖춘 semantic aware diffusion feature을 향상시키려한다.
2_2. 2D인식을 위한 Diffusion model
Train된 Diffusion model 은 Dense perception tasks 작업에 적합하다. 또한 라벨 효율성이 좋다. auxiliary network 를 사용해 잔여 특징을 출력하는 segmentation map 을 출력하도록 훈련된 모델처럼, 우리 모델에서는 ControlNet을 사용해 diffusion model 특징을 정재하여 3D 인식을 부여하였다. DiffusionDet는 target image 조건에 맞게 bounding box를 직접적으로 denoising함으로써 2D detection을 위한 diffusion model에 대한 방법론을 제시했다. Diffusion Feature는 서로 다른 UNet 레이어 활성화가 서로 다른 수준의 이미지 세부 사항과 상관관계가 있음을 이용할 수 있습니다. 우리는 이를 이용해 어떤 UNet output을 기하학적인 조건에 맞게 왜곡할지를 선택합니다. 또한 우리의 3D-aware features이 view change에 robustness를 강화할 수 있습니다.
2_3. Diffusion model에서의 Novel View Synthesis 발전과정
이미지 합성 task는 2D diffusion model의 발전과 함께 많은 변화를 겪었다. 주목할만한 연구들로는 여러개가 있는데, 이런 모델들은 Novel View Synthesis (NVS) task로 확장되었다. NVS task는 image를 넣었을때 주어진 시점으로 image로 변경되는 image to image task이다. 이런 시점 합성 모델은 카메라 주석이 포함된 합성 데이터셋에서 학습되며 실제 환경에서의 이미지도 학습 없이도 잘 일반화할 수 있다.
우리의 접근과 가장 관련있는 작업은 SparseFusion이다. 그러나 처음부터 학습되는 SparseFusion 모델과 달리 사전 훈련된 diffusion feature를 3D 인식 능력과 함께 향상시키기 위해, Novel View Synthesis(NVS)를 보조 작업으로 사용한다. 그리고 ContorlNet을 도입하여 기존의 사전 훈련된 모델의 파라미터를 최대한 유지하면서도, 필요한 부분만을 미세 조정하여 효율적으로 학습한다.
3. Method
확산 모델의 feature을 활용하여 3D 탐지를 수행하려 합니다.
이 그림 3번에서 (R1,T1)이 여러개 있는 것 같은데 이렇게 (R,T)쌍의 개수를 넣어준 만큼 여러 합성된 새로운 시점의 사진이 생성될 수 있습니다. 그림 2번을 보시면 알 수 있듯이, 3D Detection Head에는 최종 생성된 이미지가 입력으로 들어가지가 않습니다. 따라서 그림 1번에서 학습할 때는 이미지를 끝까지 생성하겠지만, 그림 3번 과정에서는 꼭 이미지를 생성할 필요는 없기 때문에 생성하지 않을 수도 있습니다.
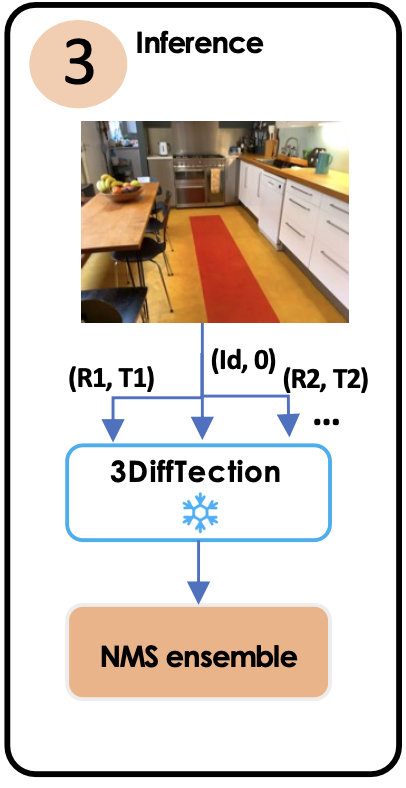
Inference시에는 (R,T)쌍의 개수만큼의 합성된 새로운 시점 사진을 만드는 과정에서 얻어진 multi-scale U-net feature들로 3D Detection 작업을 수행하여, bbox에 해당하는 좌표값+확률들만 나올수 있다고 이해하고 넘어가면 될 것 같습니다.
3_1. 3DiffTection 핵심 구성 요소
- 뷰 생성을 위한 geometric ControlNet을 훈련시켜 Diffusion Feature에 3D 인식을 부여합니다.
- 대상 데이터 분포에서 3D detection head와 동시에 훈련되는 semantic ControlNet을 사용하여 도메인 및 작업 간의 격차를 연결합니다.
- 가상 뷰 앙상블링 전략(NMS)을 통해 3D 박스 예측을 증폭시킵니다.
3_2. feature extractor로서의 확산 모델
최근 연구들은 Stable Diffusion과 같은 text-to-image diffusion model로부터 추출된 특징들이 Dense perception tasks에 적합한 풍부한 의미를 포착한다고 주장한다. 이 연구에서는 3D Object Detection에 관심이 있다. 그러나 Stable Diffusion이 2D image-text쌍에 훈련되어있기때문에 text 의미와 2D visual feature를 일치시키는데 능숙하지만 3D 인식이 부족하다. 우리는 view간의 Point대응을 조사하여 이를 탐구하고자한다. 3D 인식을 가진 특징이 multiple-view image를 제공받았을때 같은 3D 위치를 가리키는 대응을 식별할 수 있는 능력을 보여줄것이라고 가정한다.
우리 모델은 feature extraction을 위해 single forward step을 사용하지만, 실제 시나리오에서처럼 객체 탐지를 위해 텍스트 캡션 없이 이미지만을 입력한다. 이미지 x가 주어지면, 시간 t 에서 노이즈 이미지 x_t를 샘플링하고, 다음과 같은 확산 특징을 얻는다.
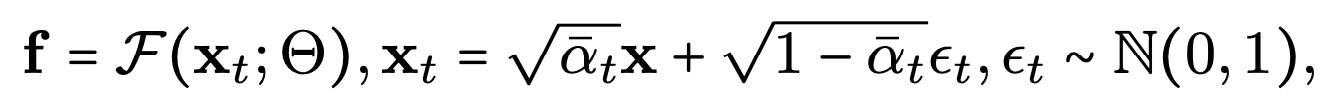
F는 U-net 디코더 모듈에서 추출된 다중 스케일 특징이다. 이는 입력 이미지 x_t로 부터 다양한 해상도의 feature map을 추출하는 과정이다. F는 U-Net 네트워크를 나타내며,Θ는 네트워크의 파라미터들을 나타냅니다.
x_t는 시간 t에서의 노이즈가 추가된 이미지이다. 다시 말해, 원본 이미지 x에 스케일링을 적용한 부분과 노이즈 성분을 합친 것이라고 볼 수 있다.

Stable Diffusion 모델의 특징들은 2D 외형 매칭(appearance matching)에 의존한다. 이는 반복되는 visual pattern이 있을때 혼란을 초래할 수 있으며, 이것은 3D 공간 이해가 부족하다는 의미이다. 이 문제를 해결하기 위해 확산모델특징에 3D 인식을 통합하는 것을 목표로한다.

3_3. 확산모델특징에 3D 인식을 통합하기
ControlNet
ControlNet은 사전훈련된 static Stable Diffusion 모델에 조건부 정보를 추가할 수 있는 강력한 도구이다. depth, semantic images와 같은 다양한 유형의 dense input 조건을 지원하는 것으로 입증되었다.
짧게 말하면, stable diffusion의 모든 파라미터를 잠근 다음, 복제한다.
이렇게 복제된 파라미터는 외부 조건 벡터로 학습된다. 조건 벡터는 zero convolution으로 한번 씌워져 복제된 파라미터와 concat되고, 그렇게 나온 결과값에 다시 zero convolution이 씌워져서 이전의 원래 파라미터와 concat된다.
구성요소
- ControlNet은 인코더,디코더 각각 12개씩, 중간 block을 포함해서 총 25개의 block으로 구성이 되며 이 중에 8개의 block들은 downsampling, upsampling Block이다. 남은 17개의 block은 각각 4개의 resnet layer와 2개의 vit들을 가지고 있다. 이때 vit는 몇개의 cross attention과 self attention mechanism을 포함하고 있다.
- ControlNet은 Stable Diffusion model의 U-net구조에서 Middle, Decoder Block에서 zero-convolution된 학습된 조건부 정보를 추가한다. 이를 통해 정교한 제어가 가능하다. 이때 학습된 조건부 정보는 feature map 형태의 깊이 정보, 또는 의미론적 정보이다. 이 feature map 형태의 조건부 정보가 zero convolution을 통해서 처리되고, 이렇게 변환된 조건부 정보가 기존 feature map과 결합됩니다. zero convolution은 학습을 통해 점진적으로 중요한 역할을 하게 된다.
- 초기에는 모든 필터가 0으로 설정되므로, zero convolution 레이어는 입력을 그대로 전달한다. 모델의 초기 출력이 변화하지 않음을 보장한다. 하지만 학습 과정에서 zero convolution의 파라미터가 업데이트되면서, 조건부 정보가 점진적으로 모델에 통합된다.
- 텍스트는 OpenAI CLIP으로 인코딩되고 diffusion timestep은 위치 인코딩으로 인코딩된다.
Zero Convolution
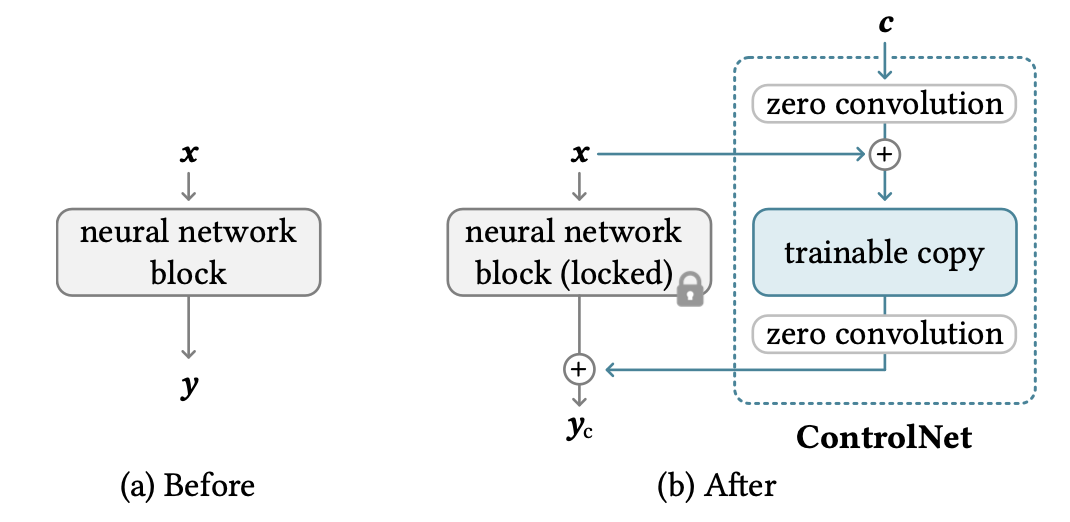
zero convolution은 네트워크 블록을 연결할때 Zero-initialized 레이어를 사용하는 하나의 방식이다. 가우시안 초기화 방식을 사용한다면 무작위 값에서 파라미터 값이 시작하기때문에 초기단계에서 모델의 출력이 불안정하게 만들 수 있지만, zero convolution 은 초기 입력에 거의 영향을 미치지 않으므로 보다 안정적으로 훈련될 수 있다.
zero convolution layer의 목적은 다양한 조건부 정보를 효과적으로 처리하고 모델의 다른 부분들과 통합할 수 있도록 변환하는 것이다.
Epipolar warp operator 개념

위 그림과 같이 3D 공간상의 한 점 P가 영상 A에서는 p에 투영되고, 영상 B에서는 p'에 투영됐다고 하면 두 영상 좌표 p와 p' 사이에는 다음 관계를 만족하는 행렬이 항상 존재한다는 것이 epipolar geometry의 핵심이다. (단, p, p'은 normalized 이미지 평면에서의 homogeneous 좌표임)
*normalized 이미지 평면 : 카메라의 내부 파라미터를 고려하여 이미지 평면을 표준화한 것이다. 카메라 내부 파라미터를 제거한 좌표계를 사용하여 표현된다. 즉, 카메라 센서의 실제 크기나 해상도에 독립적이다.
*Homogeneous 좌표는 2D 점을 3D 벡터로 확장하여 표현하는 방법이다. 예를 들어, 2D 점 (x, y)는 homogeneous 좌표 (x, y, 1)로 표현된다.
에피폴라기하학 참고할 블로그 : https://darkpgmr.tistory.com/83
[영상 Geometry #7] Epipolar Geometry
(3D 비전 geometry 마지막 6번째 파트 epipolar geometry입니다) 6장 epipolar geometry를 마지막으로 '영상 geometry' 글을 마무리하고자 합니다. 6. Epipolar Geometry Epipolar geometry는 스테레오 비전(stereo vision) 즉, 2-vi
darkpgmr.tistory.com
Epipolar Warp Operator는 ControlNet을 통해 view 합성을 수행하여 확산 모델의 3D 인식을 향상시키는 방법이다. view 합성이란 여러 시점에서 촬영된 이미지를 기반으로 새로운 시점에서 이미지를 생성하는 것을 말한다.
Epipolar Warp Operator를 사용해서 소스 뷰 이미지(condition_camera)를 다른 기하학적 위치 변환을 적용한 타겟 뷰 이미지(target_camera 새로운 시점에서의 이미지)를 생성한다.
Aggregator는 에피폴라 라인 상의 여러 특징을 하나의 출력 특징으로 결합하는 역할을 한다.

여기서 F나 세타 아래첨자 s의 의미는 정의되지 않았다.

G는 epipolar warp operator로 소스 뷰의 특징을 target view 특징으로 일치하도록 변환한다.
1. 에피폴라 라인 샘플링 : 에피폴라 기하학을 통해 에피폴라 라인 l_c를 계산한다.

2. 특징 집합 생성 : 에피폴라 라인 상의 샘플링된 특징들은 ${c(p_i)}$ 로 표시될 수 있다.
- 점 P의 특징(Ex. 색상, 텍스처, 에지)
3. 집계과정 : epipolar line을 따라 소스 이미지의 특징을 샘플링하여, 이를 목표 뷰 위치 (u,v)에서의 특징으로 집계한다. 이때 특징들을 결합하는 $aggregator$ 는 $Transformer$와 같은 복잡한 함수이다.
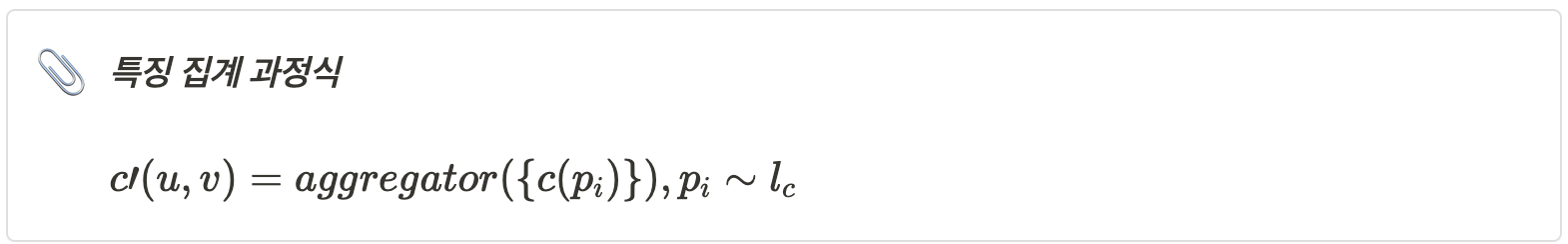
3_4. domain, task 격차를 연결하기 : 3D Det head
3D 감지를 위해 3D로 강화된 특징들을 사용한다. 이를 위해 3D Det head를 3D Box supervision아래에서 훈련한다. 미세 조정된 특징들을 Frozen시키고 3D Det head를 훈련한다.
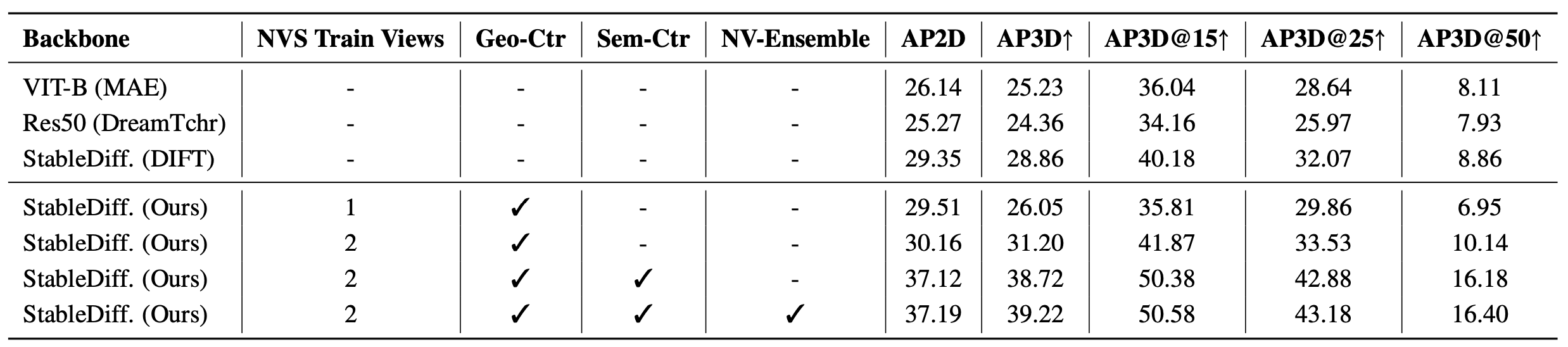
3D Det head가 있을때 기존의 베이스라인 Stable Diffusion 특징들과 비교했을때 위 표와 같은 개선점들이 있었다. 다양한 backbone모델들과 이 논문의 StableDiff를 사용한 2D 및 3D 감지 성능 지표들을 비교해봤을때 StableDiff가 성능이 우수함을 볼 수 있다.
지표에서는 Omni3D-ARKitScenes 데이터셋을 사용하였다.
AP2D : 2D 객체 감지에서 사용되는 성능 지표(AUC), AP3D : 3D 객체 감지에서 사용되는 성능 지표 ( @ 뒤에 붙은 것은 각도 오차를 고려한 세분화된 성능 지표이다.)
하지만 두 가지 잠재적인 차이로 인해 추가적인 조정이 필요했다.
첫 번째 차이는 view synthesis tuning을 할때 많은 Pose 이미지 쌍을 사용해 진행된다.
두 번째 차이는 학습된 특징들이 view synthesis를 위해 튜닝된 특징들이기 때문에 강력하고 일반적인 3D 특징을 제공하지만 3D Detection 작업에 최적화된 특징들은 아니다. 따라서 3D Detection을 위한 Feature들이 필요한 것이다. 예를 들어, 물체의 경계, 위치, 크기등의 정보를 정확하게 추출할 수 있는 특징들이 필요하다.
따라서 우리는 semantic ControlNet을 도입하여 3D 감지 작업에 최적화된 특징들을 학습하려는 접근 방식을 도입했다.

3_5. 앙상블 예측
ControlNet을 활용한 예측 앙상블을 통해 3D 탐지 성능을 더욱 향상시킬 수 있다.
우리의 박스 예측 Y는 입력 뷰에 따라 달라진다. 우리의 3D 탐지 모델이 훈련시에는 항등변환이 적용된 상태에서 데이터를 사용한다. (입력 데이터는 고정된 view에서 변환없이 사용된다.) 하지만 테스트 시에는 ξ_i로 나타내는 다른 뷰 변환(다양한 각도에서 동일한 물체를 보도록 변환이 적용된 이미지)을 포함시킬 수 있다. 이러한 다양한 각도에서의 예측 결과를 결합하여 최종 예측을 만들어 다양한 뷰 포인트를 고려한 정확한 탐지를 가능하도록 한다.


이 단계에서 새로운 뷰를 생성하는 것이 목표가 아니라, 원래의 포즈와 가까운 뷰를 사용해 예측을 풍부하게 하는 것이 목표이다. 근본적인 직관은 detection과 view synthesis 능력이 서로를 보완한다는 것이다. 특정 객체는 약간 변경된 뷰에서 관찰될때 더 정확하게 위치를 파악할 수 있다.
4. 실험
4_1. 데이터셋
Geometric ControlNet 은 ARKitscene 데이터셋을 사용하여 훈련시켰다.

45만개의 Pose가 지정된 저해상도(256x256) 이미지를 제공.
- Pose : 카메라의 위치와 방향을 포함한 전체적인 상태
- 위치(Translation) : 카메라의 3D 공간 내의 위치 x,y,z
- 방향(Rotation) : 카메라가 바라보는 방향을 나타내는 회전 행렬 또는 쿼터니언 (예: 회전 행렬 R 또는 쿼터니언 [Θ_x, Θ_y, Θ_z]
intrinsic(카메라 내부 특성)과 extrinsic(카메라 위치와 방향)을 가진 약 4만개의 RGB 이미지를 sampling한다.
- ARKitscene은 실내 장면 이해 데이터셋으로 고해상도 깊이 맵, 수동으로 라벨링된 3D 방향성 바운딩 박스, 원본 데이터, 전처리된 데이터로 구성되어있다. ARKitscene 데이터셋은 Apple의 ARKit을 이용하여 수집된 데이터셋으로 ARKit의 기능을 활용하여 pose가 지정된 이미지를 제공한다.
- Intrinsic Parameters : 카메라나 렌즈 시스템에 관한 parameter (카메라 내부 변수로서 2D상에서와 실생활간의 왜곡에 대한 보정이 가능하도록 하는 변수)
- 초점 거리
- 주점 거리
- 비대칭 계수
-
- 위치 (Translation Vector): 카메라의 3D 공간 내의 위치를 나타내는 벡터 T
- 방향 (Rotation Matrix): 세계 좌표계에서 카메라 좌표계로의 회전을 나타내는 행렬 RExtrinsic Parameters : 외부 파라미터는 주로 카메라 캘리브레이션 과정에서 사용되며 카메라 좌표계를 세계 좌표계에 정렬하는 데 필요한 변환을 나타내는 변수이다.
3D Detection train을 위해서는 Omni3D 데이터셋을 사용한다.

- 이 데이터셋은 ARKitScenes, SUN-RGBD, HyperSim, 2개의 자율 주행 데이터셋을 결합한 것이다. (ARkitScenes를 주요 실험용 데이터셋으로 사용, SUN-RGBD 및 indoor를 교차 데이터셋 실험에 사용, 성능을 평가하기 위해 ARkitScenes의 모든 카테고리에서 다양한 IoU3D 임계값 [0.05, 0.10, ..., 0.50]에 걸쳐 평균 AP3D를 계산한다. 또한 AP3D@15, AP3D@25, AP3D@50를 보고한다.)
- Omni3D 데이터셋은 Indoor and outdoor scenes 모두 존재하며 RGB 이미지, depth map, 카메라 포즈 정보, 3D 바운딩 박스, 객체 카테고리 정보들이 있다.
- Stable Diffusion model로는 text-to-image LDM을 백본으로 사용한다. 이전의 Diffusion model들이 새로운 뷰 합성 작업을 위해 여러 이미지를 필요로 하는 것과 달리, 우리는 소스 뷰와 타겟 뷰의 두 개의 뷰만 사용한다. 또한 겹침이 30% 미만인 두 개의 뷰만 고려한다.
- 새로운 뷰 합성 앙상블에서는 우리는 ±15도의 가상 카메라 회전을 사용하고, NMS를 통해 예측된 바운딩 박스를 앙상블한다.
4_2. 비교방식
CubeRCNN은 Fast-RCNN을 확장해 큐브 헤드를 추가하여 3D Detection 을 수행한다. 연구에서 우리는 더 강력한 3D 인지 image backbone을 제공하는 것을 목표로 하므로 Cube-RCNN을 이용한 image backbone과 비교를 한다. 구체적으로는 Pre-trained Stable Diffusion에서 가벼운 네트워크인 ResNet-50으로 지식을 증류하는 DreamTeacher 그리고 이미지 특징 추출기로 frozen된 Stable Diffusion을 직접 사용하는 DIFT와 비교한다. 추가로 multi-view 3D detection을 위해 고안된 방법인 NeRF-Det, ImVoxelNet 모델들과 같은 기준으로 비교한다. 앞선 모델들은 여러 각도의 이미지를 필요로하지만 3DiffTection은 단일 이미지에서도 효과적으로 작동할 수 있도록 설계한다.
4_3. ONMI3D-ARKITSCENES 에서의 3D Object Detection

훈련 시 다중 뷰 이미지를 사용하는 NeRF-Det-R50, ImVoxelNet과 비교했을때 AP3D모두 높아짐을 확인할 수 있다.
StableDiffusion 특징 예측을 ResNet backbone에 증류하여 인지 작업에 적합하게 만든 DreamTeacher-Res50와도 비교했을때, 높은 성능을 보였으며, 더 강력한 훈련 방식을 사용한 CubeRCNN-DLA-Aug와 비교했을때에도 6배 적은 데이터를 사용했음에도 불구하고 더 높은 성능을 보여주었다.
4_4.분석
3Difftection modules
backbone은 Frozen하여 고정시키고, 3D Det head만 훈련하는 설정을 Read-out이라고 한다. 이 설정에서는 backbone이 고정되어 가중치가 업데이트되지 않기때문에 backbone의 사전 학습된 특징을 그대로 유지하면서 새로운 예측 헤드를 학습할 수 있다.
- Stable Diffusion 모델에서 얻은 Feature가 2D segmentation task에서는 잘 쓰였음이 알려졌으나 3D detection에서는 실험된 적이 없다. 하지만 실험해본 결과 head가 안달린 vanilla Stable Diffusion features가 CubeRCNN-VIT-B, ResNet-50 DreamTeacher보다도 뛰어난 AP3D 평가치를 얻었다.
- geometric controlnet은 2D 지식은 보존한 채로 NVS trainining을 통해 3D 지식을 주입하는 것을 목표로 하였으며 read-out Setting(backbone frozen) 아래에서 AP3D와 AP2D 모두 향상된 결과를 얻었다.
- 단일 뷰 데이터로 Geometric ControlNet 을 이용하였을때 AP3D 성능이 낮아짐을 확인하였으므로 소스 뷰와 타겟 뷰를 다르게 설정하는 Multi view 를 이용하는 것이 더 좋음을 확인
- Semantic ControlNet을 이용하여 3D Detection 능력이 좋아짐을 확인
- NVS-ensemble 을 이용하여 3D localization 능력이 더 좋아짐을 확인
Cross-dataset experiments

Geometric ControlNet이 다른 데이터 셋의 3D 인식을 전달할 수 있는 능력을 평가하기 위해 ARKitscene 데이터셋에서는 Geometric ControlNet을 훈련하였고, Cross domain dataset에서는 3D Head만 훈련시켰다.
Baseline으로는 DIFT-Stable Diffusion feature를 사용해서 3D head를 훈련시켰다. 3DiffTection의 기하학적 ControlNet을 ARKitscene 데이터셋으로 훈련시키고, 다른 데이터셋에서는 3D 헤드만 훈련시켰다.
CubeRCNN과 비교했을 때, 3DiffTection은 완전히 미세 조정된 CubeRCNN-DLA보다 나은 성능을 보였다.
Semantic ControlNet과 3D Head를 함께 훈련시켰을때 나은 성능을 보였다.
** DLA34는 Deep Layer Aggregation 네트워크
Label efficiency
3DiffTection은 적은 양의 레이블로도 높은 성능을 유지할 수 있다는 가설을 테스트했다.
Omni3D-ARKitscene 데이터셋의 50%와 10% 레이블만 사용하여 실험을 진행했고, 적은 데이터 환경에서도 3DiffTection은 기존 방법들보다 훨씬 나은 성능을 보였다. 50% 레이블만으로도 100% 레이블을 사용한 이전 방법들보다 2.28 AP3D-N 더 좋은 성과를 달성하였고, 3D 헤드만 조정했을 때도 모든 파라미터를 조정한 CubeRCNN과 DreamTeacher보다 더 나은 성능을 보였다.
5. 결과와 한계
결과
- 3DiffTection은 단일 이미지에서 3D 객체를 감지하기 위한 방법으로 Diffusion model의 기능을 활용한다. 이 방법으로 3D 데이터셋 가용성 부족 문제를 해결하고 geometric, semantic tuning 을 이용해 기존 Diffusion model이 보여주었던 2D 지식을 보존한채 3D 인식 및 탐지 능력도 학습하였다. 높은 레이블 효율성과 교차 도메인 데이터에 대한 강한 적응성을 보여주었다.
한계
- Geometric Feature tuning을 하기 위해서는 정확한 카메라 pose를 가진 image pair가 필요하다.
- 이 방식은 동적인 객체가 포함되어있는 실제 환경에서의 이미지는 다루지는 않는다.
- Stable Diffusion 아키텍처를 사용하면 상당한 메모리와 실행 시간 자원이 필요하고, 3090Ti GPU에서 약 7.5 fps의 속도를 달성하는 등, 오프라인 객체 감지 작업에서는 적합하나 온라인 감지 설정에서는 추가적인 개선이 필요하다.
'AI&ML > paper review' 카테고리의 다른 글
| [paper review] ARES: An Automated Evaluation Framework for Retrieval-AugmentedGeneration Systems 논문 리뷰 (0) | 2024.05.19 |
|---|---|
| [paper review] RAG의 시작 (0) | 2024.05.02 |
| [paper review] inception의 발달 과정 (0) | 2023.04.07 |
| [ML/DL] 각광받지 못한 1등, GoogLeNet (0) | 2023.03.21 |




댓글