Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
RAG Paper Review [link]
Abstract
pretrained parametic
보통 GPT3나 T5같은 Parametric Impricit knowledge기반의 모델들은 모델 내부에 지식을 암시적으로 저장한다. 대형 데이터셋으로 사전 학습된 언어모델로 학습과정에서 획득한 지식은 내부 parameter에 저장된다. 학습 과정을 거쳐 이미 셋팅된 파라미터들이기에 재학습없이 생성과정에서 사용자가 지식 수정이 불가능하고 모델이 학습시에 보지 못한 정보를 추론해야할때 실제 지식과 관련없는 할루시네이션 문제가 발생한다는 문제점이 존재한다.
non-parametric
그런 반면 DrQA, ORQA, REALM과 같은 non-parametric memory 모델들은 Open-Domain QA Task를 위한 모델들로 지식을 사용자가 수정 및 업데이트 하는 것은 가능했지만 답변을 생성해내는 것이 아니라 관련 문서들에서 정답을 추출하는 것이기때문에 관련 문서에 해당 내용이 없다면 전혀 대답할 수 없는 상황이 생긴다. 또한 정답을 추출해오는 것이기에 답변의 정확성은 높을 수 있지만 질문의 의도나 문서의 문맥에서 벗어날 수 있다는 문제점이 존재한다.
이러한 문제점들을 해결하기 위해 RAG는 language generation을 위해서 pretrained parametic 과 non-parametric memory를 합친 모델이다. 논문에서는 text generation을 위해 RAG Forulation 2가지를 제시한다. RAG-sequence Model, RAG-Token Model 인데, 이는 천천히 알아보도록 하자.
Introduction
우선 task를 2가지로 나눌 수 있다. ODQA와 KIT이다.
ODQA(Open Domain Question Answering)
- ODQA는 모델이 사전에 정해진 도메인에 제한되지 않고 다양한 주제에 대한 질문에 답변할 수 있도록 하는 시스템이다. 사용자가 어떤 질문을 하더라도 관련 지식을 찾아내 정확한 답변을 제공하고자하는 것이 목표이다.
- ODQA의 answer에 대한 likelihood는 passage의 확률분포(주어진 질문에 대해 가능한 모든 passage 중에서 각각이 답변을 포함할 확률)와 Answer에 대한 passage의 likelihood(선택된 passage 내에서 특정 답변(span)을 찾았을 때, 그 답변이 실제로 정확할 가능성)로 분해될 수 있다.
- ODQA는 DrQA - ORQA - REALM 순서로 발전하였다. 이들은 모두 Retrieval-Reader 구조의 모델을 가진다.
- DrQA
- Wikipedia로 부터 candidate로 사용될 수 있는 문서 K개를 가지고 온다.
- 가져온 문서 K개와 questin을 Reader로 입력해서 Answer를 산출한다.
- 자연어 이해 및 정보 추출 능력을 바탕으로 DrQA가 외부 지식 데이터베이스로부터 질문에 대한 답변을 찾아내는 과정에서, 특정 지식이나 텍스트에 대한 사전 학습이나 주석(annotation)이 필요하지 않다
- 정답을 외부 DB에서 찾자는 아이디어를 제안했다.
- ORQA
- Retrieval 학습에 필요한 신호를 처음으로 정의하였다. Retrieval는 passage encoder와 question encoder로 구성되어있다.
- passage encoder : 관련 문서(또는 passage)를 벡터 공간에 표현하는 역할
- inverse Cloze Task와 같은 pre-train task로 학습이 이뤄진다.
- question encoder : 질문을 벡터 공간에 표현하는 역할
- pre-train과 fine-tuning을 통해 학습한다.
- fine-tuning시 상위 k개의 passage 중에서 실제 Answer span이 포함된 passage의 likelihood를 최대화한다.
- fine-tuning시 Answer span prediction과정에서 직접적으로 gradient를 통해 retireval 학습을 한다. Answer span의 likelihood 최대화
- Retrieval를 훈련시키자는 아이디어를 제안했다.
- REALM
- Masked Language Model을 pretrain모델로 사용하였다.
- Retrieval와 Reader를 end to end로 훈련시키자고 제안했다.

KIT(Knowledge intensive task)
- 관련된 passage를 input과 함께 고려하여 판단해야한다는 주장에서 나온 벤치마크. ODQA와 달리 Answer 토큰이 없다.
- RAG
- Reader가 아닌 generator로 변경해 KIT 수행
- FID & FID-Distill
- RAG의 구조를 scalable하게 만들자
- Atlas
- FID-Distill 구조를 pretrain하자
Methods
RAG는 Retrieval + Reader로 답변 내용을 추출하던 모델에서 Retrieval + Generator로 구조 변화를 일으킨 시작점이라 볼수 있다.
Retriever
점수 산출 방식 = $S_{retr}(p,q)$
1개의 questin에 대해 KB에 존재하는 모든 passage에 대한 점수를 내게 된다. passage encoder와 question encoder가 존재하고, 각각 인코딩된 hidden represent vector값들의 내적값으로 점수를 낸다.
이 점수가 높으면 높을 수록 해당 passage가 Answer 추론시 중요하게 작용될 확률이 높다는 것을 의미한다.
RAG에서는 DPR Query Encoder를 사용하여 관련 문서를 찾는다.
Reader
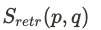
Bert Model에 passage와 question을 태워서 answer span의 logit 값을 구한다.
Reader에 의해 산출되는 각 span 별 answer 점수가 나오게 된다. 각 passage마다 각 span 별로 answer 후보에 대한 Logit 값을 구해서 이를 marginalize해서 최종 answer을 구한다.
Generator
RAG-sequence Model
- Question과 각 passage pair를 generator에 넣어 나온 output 별로 p(a|q)를 구현한다.
- Decoding 과정에서 모든 passage를 탐색하는 것이 아니라, beam search와 같은 탐색 기법을 사용하여 가능성 높은 답변을 선택합니다.
- Decoding과정에서 탐색되지 못한 passage별 문장이 존재한다. 이럴 경우 해당 문장을 모델에 forwarding 하여 logit 계산을 하게 되는데 beam size가 크면 이마저도 연산량이 굉장히 커지기 때문에 그냥 logit을 0으로 간주하는 방법을 사용한다.
- Retrieval passage수가 많을 경우 성능이 개선된다.
RAG-Token Model
- 답변을 생성하는 과정에서 하나의 토큰(단어)마다 검색된 passage들로부터 가중합을 구하여 다음 토큰을 예측합니다. 이는 각 위치에서 가장 적절한 단어를 선택하기 위해 관련 passage들의 정보를 통합하는 방식입니다.
- RAG-token은 앞에서부터 차례대로 하나의 위치씩 답변을 예측해 나가며, 이 과정에서 생성된 답변은 순차적으로 쌓입니다. 이 구조는 자연어 생성에서 일반적으로 사용되는 접근 방식과 비슷하다.
- RAG-token 모델은 검색된 passage의 수가 일정 수준을 넘어서면 성능이 저하될 수 있습니다. 너무 많은 정보를 동시에 처리하려고 할 때 정보의 중요성을 효과적으로 균형잡기 어려워지기 때문이다. → Fusion-in-Decoder(FiD), FiD-Distiill로 극복이 가능하다. FiD는 여러 passage의 정보를 효과적으로 통합하여 한 번에 처리할 수 있는 방식을 제공함으로써 성능 저하 문제를 해결할 수 있다.
RAG에서는 BART 의 encoder와 decoder를 사용해 모델링하여 output을 생성한다.
Results
retireval와 generator를 결합하는 방법론을 제시하였으며, retrieval에 대해 end to end로 학습하여 성능을 개선하였다.
generator를 사용하면서 다양성이 증가되었고 할루시네이션 효과는 감소되었다.
외부지식을 사용할 수 있게 되면서 Knowledge Base를 수정할 수 있게 되었다.
REALM에서 RAG로 발전했을때 변한 부분
- span prediction task → answer generation task
Jeopardy Question Generation
- 주어진 입력(예: "Hemingway")에 대한 문맥을 이해하고, 관련 문서를 검색한 후 그 내용을 바탕으로 텍스트를 생성합니다.
- 질문 생성 태스크에서 모델이 "The Sun Also Rises"라는 답변에 대한 질문을 생성하려 할 때, 모델은 문서 2의 정보를 더 높은 확률로 참조한다. 반면 "A Farewell to Arms"에 대한 질문을 생성할 때는 문서 1을 더 높은 확률로 참조한다. 이 확률 분포는 입력 텍스트와 문서 간의 관련성을 나타내며, RAG 모델이 어떻게 문서를 검색하고 그 정보를 생성 과정에 통합하는지를 보여준다.
FEVER(Fact Extraction and verification)
자동화된 사실 확인을 위한 대규모 데이터셋
Abstractive question answering
주어진 정보를 이해하고, 그 내용을 바탕으로 새로운 형태의 응답을 추론
RAG Sequence 논문에서의 logit이란?
디코딩 과정에서 "logit"이라고 언급되었을 때, 이는 모델이 각 단어 또는 토큰에 대한 예측을 내리기 위해 계산하는 값입니다. Logit은 모델의 최종 출력층에서 나온 원시 점수(raw scores)를 말하며, 이 점수는 softmax 함수를 통해 확률로 변환되기 전의 값입니다. 각 logit은 특정 단어의 확률을 나타내기 전 단계의 값으로, 높은 logit 값은 모델이 해당 단어를 다음 단어로 예측할 확률이 높다는 것을 의미한다.
'AI&ML > paper review' 카테고리의 다른 글
| [paper review] 3Difftection: 3D Object Detection with Geometry-aware diffusion features (2) | 2024.07.07 |
|---|---|
| [paper review] ARES: An Automated Evaluation Framework for Retrieval-AugmentedGeneration Systems 논문 리뷰 (0) | 2024.05.19 |
| [paper review] inception의 발달 과정 (0) | 2023.04.07 |
| [ML/DL] 각광받지 못한 1등, GoogLeNet (0) | 2023.03.21 |




댓글